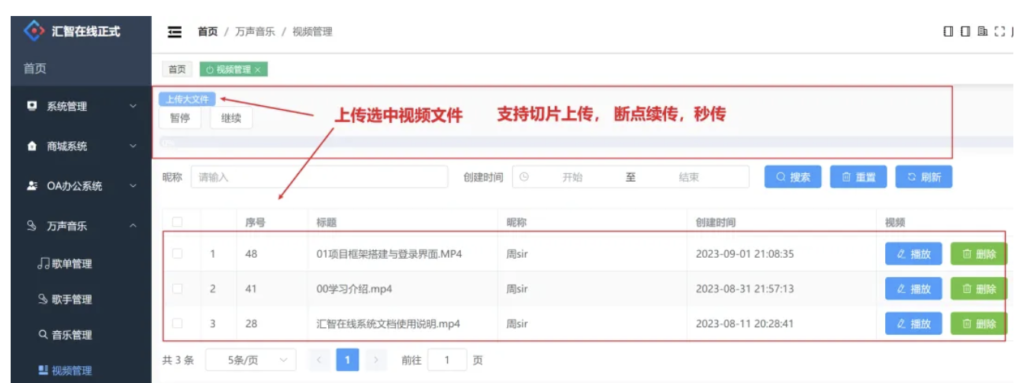
李小萌同学经过上次面试失败后,努力提升自己技术,终于入职一家软件公司。公司Leader给小萌分配了一个上传视频文件任务,要求支持切片上传,断点续传,秒传功能。
小萌只做过基础的图片文件上传,对于大文件切片上传经验不够,但这难不到小萌,谁叫咋是程序员呢,学习是我们的第一生产力。小萌首先查阅互联网,问了问百老师,接着写了个大文件切片上传Demo,这个Demo包含两个文件,一个后端文件app.js,实现了接收上传文件,合并文件和检验文件功能。另一个是前端文件upload-1.html,负责实现界面。
运行效果如下图,下面我们就来看下小萌的大文件切片上传是如何实现的。
01 大文件切片上传前端实现
大文件切片上传最大的好处是防止网络不好的情况下文件上传一半挂掉,下次得全部重新上传。
实现思路是利用前端将一个大文件,拆分成多个小文件(分片);前端将拆分好的小文件依次发送给后端(每一个小文件对应一个请求);后端每接收到一个小文件,就将小文件保存到服务器;当大文件的所有分片都上传完成后,前端再发送一个“合并分片”的请求到后端,后端对服务器中所有的小文件进行合并,还原完整的大文件。

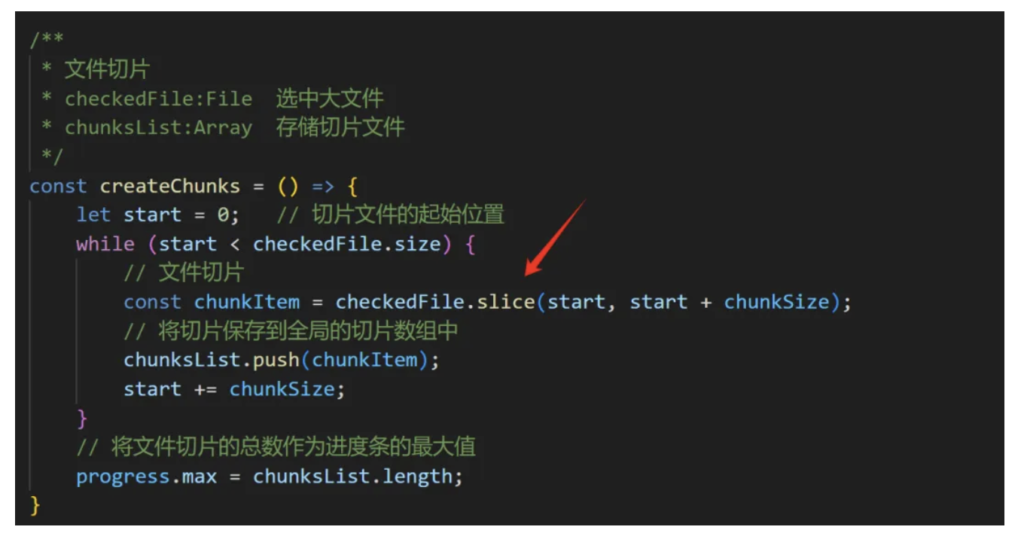
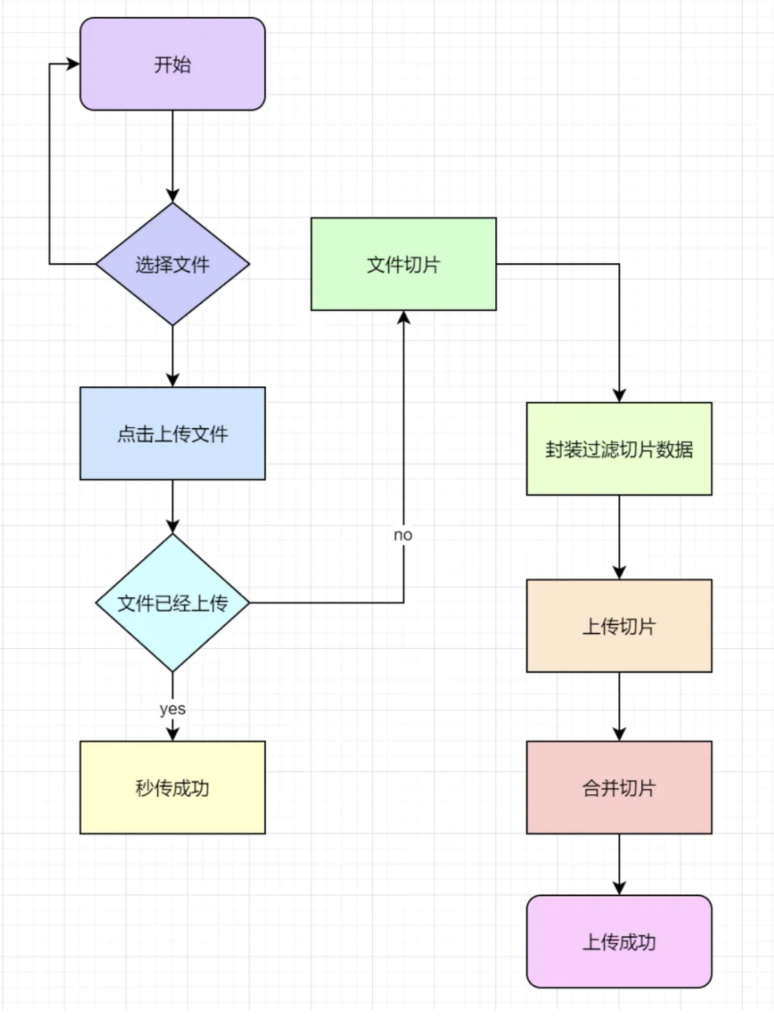
1. 文件切片
使用File对象的slice() 方法实现, 参数不清楚的查阅MDN
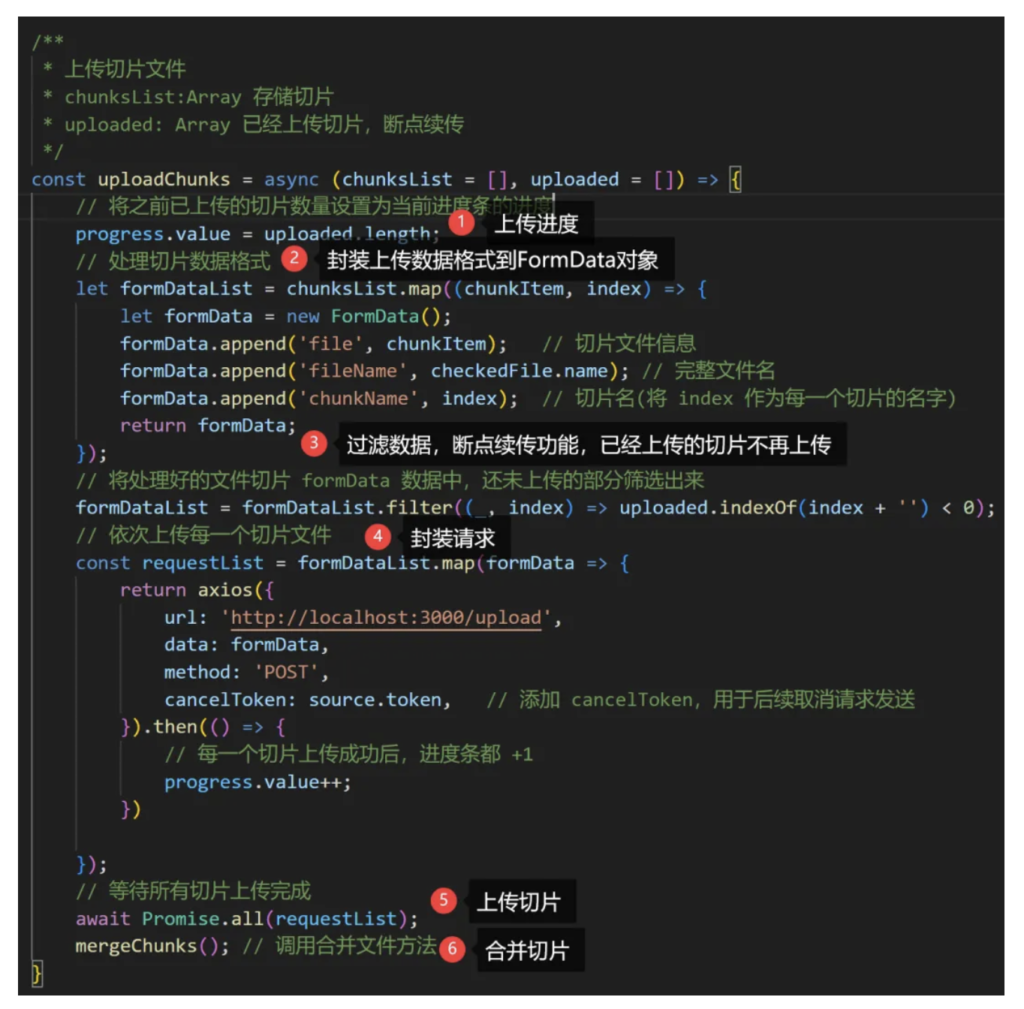
2. 上传切片文件
使用FormData对象封装上传数据,过滤已经上传过的切片,使用axios库上传切片文件,cancelToken属性终止axios网络传输暂停文件上传。
3. 合并切片
合并切片功能主要后端实现,前端负责调用合并接口

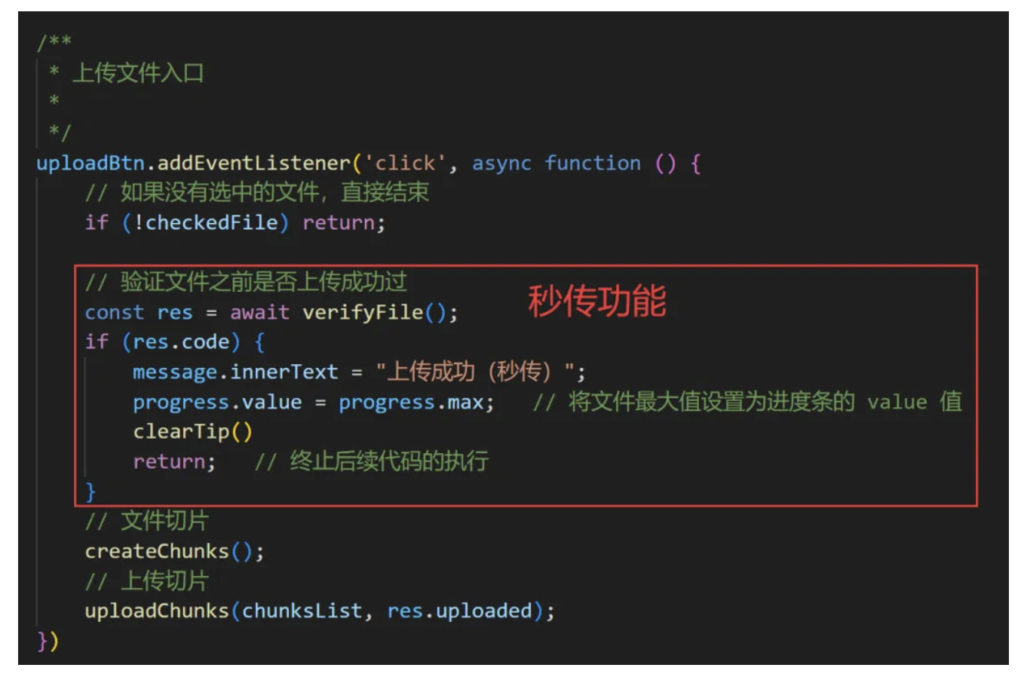
4. 秒传文件
秒传文件本质是检查到后端已经有上传文件,直接显示秒传成功
5. 实现流程图
02 大文件上传后端实现
后端采用nodejs技术实现,文件上传使用multiparty 库,文件读写使用fs-extra库。主要实现三个接口,文件上传接口,文件合并接口和检验文件接口。
// 上传的切片文件的存储路径
const ALL_CHUNKS_PATH = path.resolve(__dirname, 'chunks')
// 切片合并完成后的文件存储路径
const UPLOAD_FILE_PATH = path.resolve(__dirname, 'public/files')
/**
* 文件上传接口
*
*/
app.post('/upload', async (req, res) => {
const multipartyForm = new multiparty.Form()
multipartyForm.parse(req, async (err, fields, files) => {
if (err) {
res.send({
code: 0,
message: '文件切片上传失败',
})
return
}
// 前端发送的切片文件信息
const [file] = files.file
// 前端发送的完整文件名 fileName 和分片名 chunkName
const {
fileName: [fileName],
chunkName: [chunkName],
} = fields
// 当前文件的切片存储路径(将文件名作为切片的目录名)
const chunksPath = path.resolve(ALL_CHUNKS_PATH, fileName)
// 判断当前文件的切片目录是否存在
if (!fse.existsSync(chunksPath)) {
// 创建切片目录
fse.mkdirSync(chunksPath)
}
// 将前端发送的切片文件移动到切片目录中
await fse.move(file.path, `${chunksPath}/${chunkName}`)
res.send({
code: 1,
message: '切片上传成功',
})
})
})
/**
* 合并切片接口
*
*/
app.post('/merge', async (req, res) => {
// 获取前端发送的参数
const { chunkSize, fileName } = req.body
// 当前文件切片合并成功后的文件存储路径
const uploadedFile = path.resolve(UPLOAD_FILE_PATH, fileName)
// 找到当前文件所有切片的存储目录路径
const chunksPath = path.resolve(ALL_CHUNKS_PATH, fileName)
// 读取所有的切片文件,获取到文件名
const chunksName = await fse.readdir(chunksPath)
// 对切片文件名按照数字大小排序
chunksName.sort((a, b) => a - 0 - (b - 0))
// 合并切片
const unlinkResult = chunksName.map((name, index) => {
// 获取每一个切片路径
const chunkPath = path.resolve(chunksPath, name)
// 获取要读取切片文件内容
const readChunk = fse.createReadStream(chunkPath)
// 获取要写入切片文件配置
const writeChunk = fse.createWriteStream(uploadedFile, {
start: index * chunkSize,
end: (index + 1) * chunkSize,
})
// 将读取到的 readChunk 内容写入到 writeChunk 对应位置
readChunk.pipe(writeChunk)
return new Promise(resolve => {
// 文件读取结束后删除切片文件(必须要将文件全部删除后,才能外层文件夹)
readChunk.on('end', () => {
fse.unlinkSync(chunkPath)
resolve()
})
})
})
// 等到所有切片文件合并完成,且每一个切片文件都删除成功
await Promise.all(unlinkResult)
// 读取所有的切片文件,获取到文件名
const chunksNameTemp = await fse.readdir(chunksPath)
if (chunksNameTemp.length === 0) {
// 删除切片文件所在目录
fse.rmdirSync(chunksPath)
res.send({
code: 1,
message: '文件上传成功',
})
}
})
/**
* 校验文件接口
*/
app.post('/verify', async (req, res) => {
// 获取前端发送的文件名
const { fileName } = req.body
// 获取当前文件路径(如果上传成功过的保存路径)
const filePath = path.resolve(UPLOAD_FILE_PATH, fileName)
// 判断文件是否存在
if (fse.existsSync(filePath)) {
res.send({
code: 1,
message: '文件已存在,不需要重新上传',
})
return
}
// 断点续传:判断文件是否有上传的一部分切片内容
// 获取该文件的切片文件的存储目录
const chunksPath = path.resolve(ALL_CHUNKS_PATH, fileName)
// 判断该目录是否存在
if (fse.existsSync(chunksPath)) {
// 目录存在,则说明文件之前有上传过一部分,但是没有完整上传成功
// 读取之前已上传的所有切片文件名
const uploaded = await fse.readdir(chunksPath)
res.send({
code: 0,
message: '该文件有部分上传数据',
uploaded,
})
return
}
res.send({
code: 0,
message: '文件未上传过',
uploaded:[]
})
})
03 总结
小萌写完Demo并没放松,很多功能还需要完善。如大文件切片上传切片名用的索引号,正式项目应该生成hash码更加稳妥。上传切片没有考虑并发上传,后期应该使用pLimit库优化。