什么是索引?
索引是数据库表中的字段的索引,所谓的索引就是在表的字段上添加的,每个字段都可以添加索引来提高查找效率,也可以多个字段联合添加一个索引。
参考字典的实现,索引相当于字典的目录,通过目录缩小查找范围。
索引的实现原理
假设有一张用户表:t_user
id(PK) name 每一行记录在硬盘上都有物理存储编号
----------------------------------------------------------------------------------
100 zhangsan 0x1111
120 lisi 0x2222
99 wangwu 0x8888
88 zhaoliu 0x9999
101 jack 0x6666
55 lucy 0x5555
130 tom 0x7777
提醒1:
在任何数据库当中主键上都会自动添加索引对象,id字段上自动有索引,因为id是主键。另外在mysql当中,一个字段上如果有unique约束的话,也会自动创建索引对象。
提醒2:
在任何数据库当中,任何一张表的任何一条记录在实际硬盘存储上都有一个硬盘的物理存储编号。
提醒3:
不管索引存储在哪里,索引在mysql当中都是一个树的形式存在。(自平衡二叉树:B-Tree)
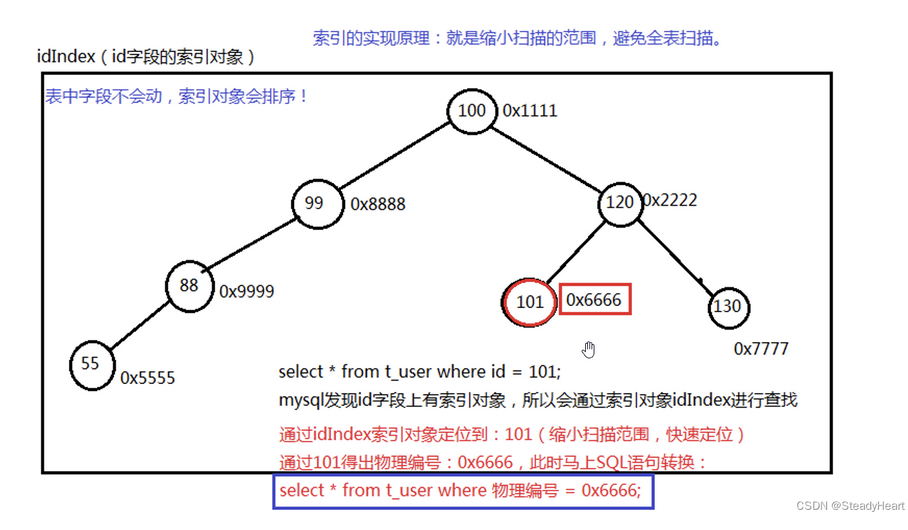
假如sql语句是:select * from t_user where id = 101; 条件是id = 101,mysql发现id字段上有索引对象,所以会通过索引对象进行查找: 101比100大,看右边 101比120小,看左边 定位到101,通过定位到的101得出对应的物理编号0x6666,就会转换sql语句成: select * from t_user where 物理编号 = 0x6666; 直接通过物理编号0x6666定位到存储的记录 101 jack 0x6666, 返回给用户。 假如id字段没有索引的话,他会到id字段上,进行从上到下查找,直至找到101,效率很低。
什么时候考虑添加索引?
什么条件下,我们会考虑给字段添加索引呢?
条件1:数据量庞大(到底有多么庞大算庞大,这个需要测试,因为每一个硬件环境不同) 条件2:该字段经常出现在where的后面,以条件的形式存在,也就是说这个字段总是被扫描。 条件3:该字段很少的DML(insert delete update)操作。(因为DML之后,索引需要重新排序。)
建议不要随意添加索引,因为索引也是需要维护的,太多的话反而会降低系统的性能。
建议通过主键查询,建议通过unique约束的字段进行查询,效率是比较高的。
索引的类型
分单列索引、组合索引和全文索引
单列索引:
主键索引,数据库表的主键字段会自动创建索引。
唯一索引,当某个列添加了Unique约束,也会自动创建唯一索引,要求值必须是唯一的。
普通索引,给普通字段添加索引就是普通索引。
组合索引:
多个字段合起来创建一个索引,只有当查询条件中使用了组合索引的第一个字段,索引才会被使用,使用组合索引是遵循最左前缀原则。
CREATE INDEX index_id_name ON mytable(id,name);
为什么要有索引?
为了提高查询的效率。
怎么用索引?
创建索引:
create index 要创建的索引名 on 要创建索引的表名(要创建索引的字段);
删除索引:
drop index 要删除的索引名 on 要删除的索引所在的表名;
怎么查看一条sql语句中使用了索引?
dept表:
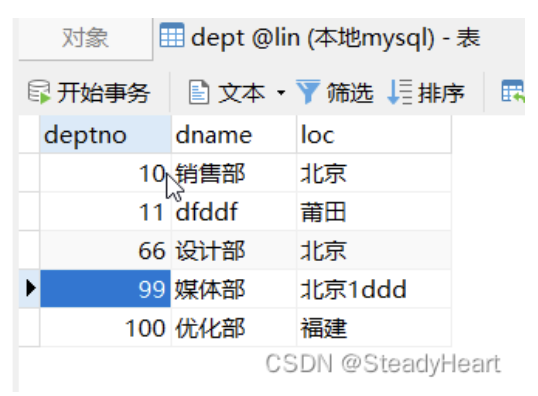
解释这条sql语句:
EXPLAIN select * from dept where loc = ‘北京’;

rows = 5,表示遍历了5条,说明是全部都遍历查找比对,找loc = ‘北京’,说明loc字段没有索引。
给loc字段添加索引:
create index locIndex on dept(loc);
再执行sql语句:
EXPLAIN select * from dept where loc = ‘北京’;

rows = 2,就是遍历了2条,说明loc字段的索引起作用了。
索引失效的情况以及对应解决方案
失效的第1种情况:
select * from emp where ename like '%T';
ename上即使添加了索引,也不会走索引,为什么?原因是因为模糊匹配当中以“%”开头了,mysql找不到。
解决方案:尽量避免模糊查询的时候以“%”开始。这是一种优化的手段/策略。
失效的第2种情况:使用or的时候会失效,如果使用or那么要求or两边的条件字段都要有索引,才会走索引,如果or其中一边有一个字段没有索引,那么另一个字段上的索引也会失效。
解决方案:不建议使用or,所以这就是为什么不建议使用or的原因。 或使用union联合查询。
举例:
dept表,loc字段有索引,deptname字段没有索引
select * from dept where loc = '福建' or deptname = '信息部';
查询位于福建的或者信息部的部门信息
以上sql语句,由于deptname没有索引,会导致loc的索引失效,可以使用union联合查询:
select * from dept where loc = '福建'
union
select * from dept where deptname = '信息部';
这样loc字段的索引还是生效的。
失效的第3种情况:使用复合索引的时候,没有用到左侧的字段作为查找条件,索引失效
什么是复合索引? 两个字段,或者更多的字段联合起来添加一个索引,叫做复合索引。
create index emp_job_sal_index on emp(job,sal);
索引正常:explain select * from emp where job = 'MANAGER';
索引失效:explain select * from emp where sal = 800;
失效的第4种情况:在where当中索引列参加了运算,索引失效。
create index emp_sal_index on emp(sal);
索引正常:explain select * from emp where sal = 800;
索引失效:explain select * from emp where sal+1 = 800;
失效的第5种情况:在where当中索引列使用了函数
ename字段有索引
explain select * from emp where lower(ename) = 'smith';
总结
数据库索引的本质是一个排序的数据结构,以协助快速查询、更新数据库表中的数据,可以理解为一种特殊的目录,实现方式通常采用B树和B+树
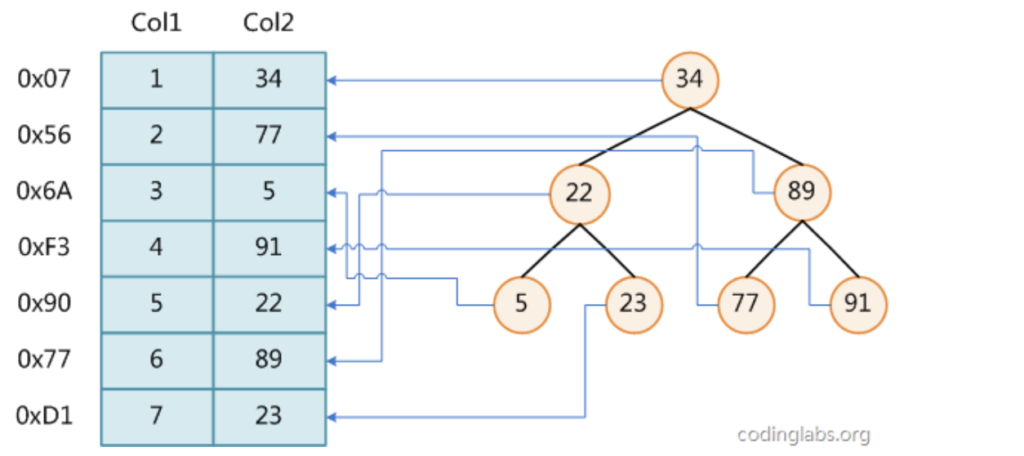
上图展示了一种可能的索引方式,左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)的复杂度内获取到相应数据。
目前大部分数据库系统及文件系统都采用B树或其变种B+树作为索引结构
创建索引可以大大提高系统的性能:
1.通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。 2.可以大大加快数据的检索速度,这也是创建索引的最主要的原因。 3.可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。 4.在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。 5.通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
但是盲目的增加索引也有很多不利的地方:
1.创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。 2.索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。 3.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。