前言
Git是一款非常受欢迎,也非常强大的版本管理工具。

但是,它的工作流程相对于SVN等其他版本管理工作也复杂很多,对于刚接触的同学会有很多操作难以理解。
例如,当我们和其他同学进行协同开发时,我们每个人都从远程仓库拉取了一份代码到本地仓库,此时每个人电脑上的本地仓库和远程仓库都是一致的。
但是,随着开发的不断推进,如果其他同事事先已经把修改的代码推送到远程仓库,当我们后面再push时就会发生冲突。
这时候,就需要先把远程代码的最新版本重新拉取一下到本地仓库,这时候,就会用到git pull和git fetch。
在这个过程中,很多同学就有点分不清了,都是拉取远程仓库的代码到本地仓库,它们的区别是什么呢?
要想理解它们的工作愿意,首先要对Git仓库有一个清晰的认识。
在我们开发过程中,代码仓库至少会有3个仓库/副本:
- 本地工作目录:也就是我们开发过程中正在编辑的工作目录
- 本地仓库:这一点是很多初学者容易忽略和搞混的,由于git是分布式的,所以每个开发者本地都会有一个本地仓库,当我们通过git commit提交代码时,更改就从本地工作目录提交到了本地仓库
- 远程仓库:这个应该大多数同学都很清楚,顾名思义,就是在远程服务器上存储的仓库,例如Github、Gitlab,当我们使用git push推送代码时,代码就从本地仓库推到了远程仓库
在很多刚接触Git的同学意识里,容易理解本地工作目录和远程目录,认为执行commit和push就是直接从本地工作目录推到了远程仓库,容易忽略本地仓库。
现在,理解了Git的工作流,接下来再解释git pull和git fetch的区别就简单多了。
就如同前面提到的,很多同事协同开发过程中并不是同步的。例如,A和B两位开发者都从远程仓库拉了一份最新数据到本地仓库,A修改了代码之后先推送到远程仓库了,这时候B的本地仓库代码和远程仓库的就不一样了。如果这时候直接push就会引起冲突。
所以,协同开发过程中,在推送代码之前,首先需要先检查一下本地仓库与远程仓库的差异,然后把最新的代码拉到本地,然后再提交、推送。
这时候就会用到git pull和git fetch,它们在完成相同的工作,只是处理方式不同。
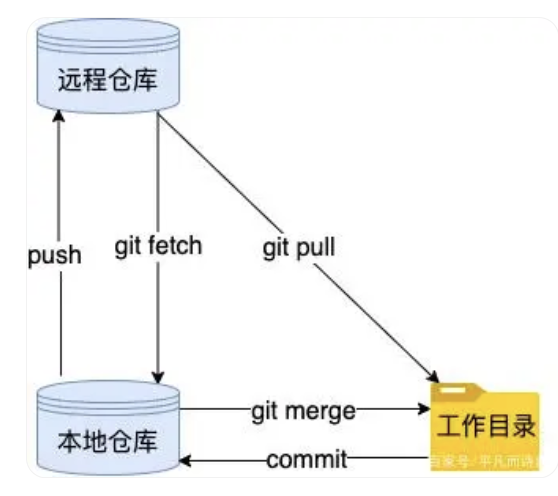

git fetch
在拉取代码过程中,git fetch会首先检查本地仓库和远程仓库的差异,检查哪些不存在于本地仓库,然后将这些变动的提交拉取到本地。
但是,这里请注意,它是把远程提交拉取到本地仓库,而不是本地工作目录,它不会自行将这些新数据合并到当前工作目录中,我们需要继续执行git merge才会把这些变动合并到当前工作目录。
git pull
而git pull 则是将远程主机的最新内容拉下来后直接合并,即:git pull = git fetch + git merge,这样可能会产生冲突,需要手动解决。
git pull和git fetch刚好相反,它直接获取远程的最新提交,直接拉取并合并到本地工作目录,而且在合并过程中不会经过我们的审查,如果不仔细检查,这样很容易遇到冲突。
理解了git pull和git fetch的区别,那么该用哪种方式呢?
相比之下,git fetch是一个更安全的选择,因为它从你的远程仓库拉入所有的提交,但不会对你的本地文件做任何修改。
这给了你足够时间去发现远程仓库自从你上次拉取后到现在为止发生的变化。
你可以在合并前检查哪些文件有变化,哪些文件可能导致冲突。
而git pull相当于运行git fetch,然后立即将你的改动合并到本地仓库。
这样的确少了一个步骤,但是也会带来一些风险。
作为一名开发者,在项目开发过程中很难绕开git,只有深入理解git的工作原理才能在工作中更加自如的应用Git完成项目协同开发,如果一直处于一知半解的状态,在版本控制中经常会遇到各种各样的问题。