前言
相信很多小伙伴跟我一样,之前很长一段时间对Unicode和UFT-8一直搞得不清不楚,等到用的时候就网上搜一搜,大概懂了点是什么,隔一段时间后又搞忘了,简直阔怕啊。今天我将带您轻轻松松出困境,用正确的姿势学习认识Unicode和UTF-8
ASCII码
由于计算机这玩意儿是英文为母语的老外发明的,在计算机发展早期,能用到计算机的也就是用英语的那么些国家,因此对于他们来说,用于表示计算机显示屏上要显示的字符也就大小写的英文字母、数字、标点符号、特殊符号、一些特殊字符再加上些控制字符就足矣,总共加起来一个字节足矣表示完。因此就出现了ASCII码。
ASCII码是从零开始编号,一直到127号,用于表示完上述所有的东西。把从0 ~ 31的32种状态用于与打印机、终端等设备“约定”为控制码,就是专门用于“控制”用途的,意思就是只要打印机啊、终端等设备啊,遇到这些0 ~ 31的控制码的时候,就会做他们约定好的动作,例如,当遇到0xA的时候,终端就会换行,这样子工作起来会很好很和谐。因此,0x20之前的这32种状态就被用作了 控制码。
之后从0x20开始依次连续的对剩余字符进行编号,直到127号,这些编号的字符包括空格、标点符号、数字、大小写字母等。这样子就能很完美的用不同的字节表示完上述所有的东西了。这就是ASCII码。
Unicode
随着计算机的发展和流行,越来越多的国家开始接触和使用到了计算机,这个时候,问题就随之而来,英文虽然简单易学,但是对于非英语国家来说,毕竟也是一门外语,也不是随随便便轻轻松松的就可以学得会的,你不可能让一个完全不懂英文的中国人很好很熟练的去使用一台只能显示英文的计算机吧,你界面做得再人性化,看不懂上面写得什么仍然是最痛苦的一件事啊,这样子也很不利于计算机的长期发展。
世界上那么多国家,那么多民族和语言,仅仅一个字节八位,总共256种状态,怎么都不能表示得了世界上这么多字符的,我们中国几千年源远流长的文化历史,光我们近现代才发展起来的简体中文,你这一个字节都是远远不够的。
因此后来ISO(International Standardization Organization 国际标准化组织)就重新制定了一套包含地球上所有文化、所有字母和符号的编码。这就是“Universal Multiple-Octet Coded Character Set”,俗称Unicode,简称UCS,也就是我们常说的通用字符集。
ASCII码制定的时候还有一个原因,就是当年计算机发展的早期,存储空间这些是很小的,对于那时候来说,存储空间是很奢侈的。记得当年比尔盖茨就说过大概这样的一句话:几KB内存的计算机是完全够用了。然而他万万没想到的是,几十年后过去了,几GB甚至成百上千GB的内存空间都可能是不够用的。刚好,在Unicode制定的时候,计算机的存储容量得到了极其大的发展,那时候存储空间已不再是奢侈的东西了,空间问题从那时开始就已经不是什么问题了,于是ISO就用更大的存储空间来制定新的规则。
ISO规定,必须用两个字节,也就是16位二进制来统一的表示所有的字符。这16位二进制的数值就被称为“code point”,也就是码点,说白了就是每个字符的编号而已,这个和ASCII码的编号是一样的概念,只是换了个名字而已。就比如,码点0x41就表示大写字母“A”。
最初的ASCII码是7位的,后来发展成了8位,因此ASCII码的范围就是0x00 ~ 0xFF。Unicode是16位的,范围就是0x0000 ~ 0xFFFF,也就是四位十六进制表示这一个Unicode字符的,比如“汉”的Unicode 码点 是 Ox6C49。
这里请注意了,这里用两个字节来表示一个Unicode字符,并不是说实际存储也是用两个字节来进行存储一个字符的。并不是这样的。在存储的时候,可以用大于两个字节的空间去存储它,就像在32位电脑上用四个字节去存储一个整数1,尽管是用一位就够了。
什么是UTF-8
从上面提到的,大家也知道了,在Unicode中,对一个字符的表示永远都是两个字节的,但是实际上,存储并不都是一直用两个字节来进行存储的。这又是为什么呢,为什么表示和存储会不一样呢?
Unicode和UTF-8的关系
通过ISO(国际标准化组织)这个组织的名字也看得出来,它是一个专门制定标准的组织,就例如著名的ISO网络七层模型,这网络七层模型就是ISO制定出来的网络通讯标准,但是呢,大家也知道,实际上我们真正网络的实现上,并没有完全套用那七层模型,而是我们熟知的TCP/IP的四层模型。这里就出现了刚提到的实现和制定的标准上的差异。请大家想想问啥会出现这样的差异问题呢?
最主要的原因其实是这样的,ISO组织里制定标准的那群人主要就是搞理论知识的,理论这些东西都是很抽象的,就像你去看大学教材《计算机网络原理》,估计可以看得你欲哭无泪吧,几乎整本书的理论知识。理论知识都是很抽象的,理解起来难度也偏大,并且跟实际应用也是有些许差异的。就像我们的中科院一样,中科院的院士都是研究理论知识的,而实际上去真正动手干的人是工程院的人,就比如我们亲爱的袁隆平爷爷,别人的动手能力直接做出了划时代意义的杂交水稻,这是实打实做出来并且应用于大众的东西。你让中科院的去做出来,这是很难的。ISO也是一样的,他们理论知识搞得很专业,但是呢,缺乏实战经验,你让他们把网络七层模型直接实现出来,用于大众,也是不现实的。因此实现网络通讯的是那些整天都做生产这些东西的厂商,他们拥有十足的实战经验,才能真正的做出广泛用于我们的生活的网络通讯协议。因此就出现了,制定的标准和实际实现上的差异的现象。
同样的,Unicode也和ISO网络七层模型一样,都是他们制定出来的抽象的理论标准,然而真正用于实际生活的实现,也是不太现实的。但是标准制定出来也是很有意义的,你制定了统一的标准,大家都参照你这个标准去实现去生产,那么就能达到统一性。
因此就出现了UTF,英文是UCS Transfer Format。UTF-8就是专门对Unicode这套理论标准的一种具体实现。UTF-8是参照Unicode标注而做出来的真正能用于实际生活的一套东西。说白了就是:Unicode是一套方案,是一个行动的“指导方针”,是理论知识,而UTF-8是这个“指导方针”的具体实现,也是其具体”行动“。而Unicode的实现也很多,UTF-8只是其中一种,还包括,UTF-16和UTF-32。重要的东西最后再重复一遍:UTF-8是Unicode的具体实现之一。
UTF-8具体实现
Unicode虽然能容纳上百万数量的字符 ,但它只是一个巨大的字符集而已,仅仅规定了每个符号的二进制代码表示,然鹅并没有制定具体的存储规则,因此它仅限于概念,没有具体落实到底该怎么去实现。因此到目前为止还只是纸上谈兵。这导致 unicode 有不少问题,比如当用 3 个字节存储一个Unicode字符的时候,它同时也可以被理解为存储了 3个大小为1字节的ASCII码,这是具有二义性的。 另外,我们之前知道ASCII码只需要一个字节,但是,如果 Unicode规定每个字符都用 3个字节来存储的话,那岂不是活生生浪费了两个字节的空间?所有这些未经细化的问题都将导致Unicode的不一致性, 因此导致Unicode在很长一段时间内无法推广。
UTF的出现,就解决了上述提到的Unicode问题,而UTF-8实现方式又是最通用和常见的一种方式了。因此我们在这里将介绍UTF-8的具体实现,让你真正认识到什么是UTF-8.
UTF-8最大的一个特征就是变长存储的编码方式。它可以使用1 ~ 4个字节去存储不同的字符,根据不同的字符选择最合适的字节长度去进行存储。这样就起到了合理利用存储空间的作用。那么UTF-8具体是怎么实现的呢?
UTF-8编码规则
UTF-8的编码规则很简单,只有两条:
- 1、对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语宇母, UTF-8编码和ASCII码是相同的 2、对于 n 字节的符号 (n>1),第 一个字节的前 n 位都设为 1,第 n+1位设为 0,后面字节的前两位一律设为 10(注意这里说的是二进制10)。剩下的没有提及的二进制位,全部为这个符号的 Unicode码
- 2、对于 n 字节的符号 (n>1),第 一个字节的前 n 位都设为 1,第 n+1位设为 0,后面字节的前两位一律设为 10(注意这里说的是二进制10)。剩下的没有提及的二进制位,全部为这个符号的 Unicode码
可以看看下图,字母 x 表示可用编码的位 :
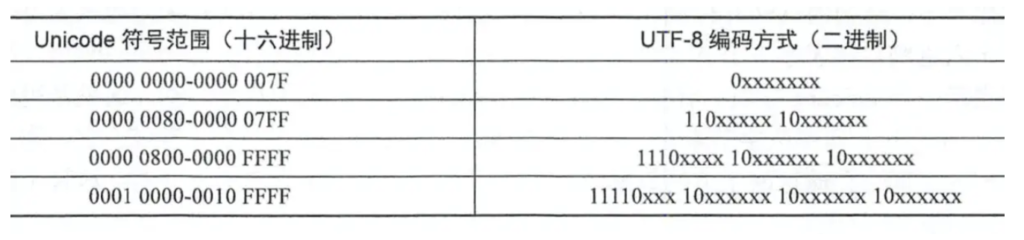
详解UTF-8编码规则
- 1、一个字节的时候
众所周知,计算机长久发展以来,随时都做得很好的一个事情就是,新的东西总是会去很好的兼容旧的东西。就例如我们的8086 CPU,现如今,CPU都发展了好多年好多代了,然而现在的CPU仍然是很好的兼容了几十年前的8086 CPU。这就是计算机界一直以来的向下兼容。
同样的,字符编码依然做好了向下兼容的事情,UTF-8也是如此。前面提到过,ASCII码是使用一个字节来表示和存储字符的,用到的是前128个数值,也就是0 ~ 127。你会发现,UTF-8照样也会遇到一个字节的情况,UTF-8遇到一个字节的时候,为了做到兼容ASCII码,它的做法就很干脆,就把最高位设为0,后七位直接使用ASCII码编码规则来进行存储。这样做完美做到了兼容ASCII码了。
- 2、大于一个字节的时候
当大于一个字节的时候,由于UTF-8编码是变长的,因此就出现了一个亟待解决的问题,就是,怎么知道当前的一个UTF-8编码到底占用几个字节空间?因此就必须得有一种方式来标记当前的UTF-8编码占用了多少个字节。
大于一个字节的时候,我们把第一个字节称为高字节,其余的所有字节都称之为低字节。当此编码用几个字节存储,那么它的高字节的前几位就为1,然后紧接着的一位设置为0。其余所有低字节的高两位固定为10。为了叙述方便,我们把高字节和低宇节中那些用以标识 UTF-8 特征的位(不能用于存储数据的位)暂称为标记位。 如果一个 UTF-8 编码占用了 n个字节,高字节的高 n位就都是 1,第 n+1 位是 0。低字节的高位均以 10 开头 。 除了各字节高位的标记位之外的其他位才是真正存储数据的位,暂称为数据位。
- 为什么第 n+1位是 0呢?
从上面我们知道,UTF-8的高字节的决定了当前编码占据多少字节。在读取的时候是怎么确定当前编码占据多少字节的呢?就是从高字节的最高位开始读取,发现是当前位是1,就加一个字节,那么,怎么知道高字节中的标记位在什么时候结束呢?我们也知道,数据位也是能存储1的,那么怎么知道在读取高字节的位数数值的时候,当前位是数据位还是标记位呢?那么,为了解决这个问题,最好的解决方法就是在标记位的所有1的后面紧跟着一个0就行了,在读取数值的时候,从最高位开始读取,当读取到第一个0的时候,就认定当前的标记位读取结束,这时候读取到多少个1,就说明当前编码占用多少个字节。就此完美解决这个问题。
- 为什么 2 字节以上(包括 2 字节)的 UTF-8 编码 ,低字节的高 2 位始终是固定的 10 呢?
我们上面提到过UTF-8会去兼容 ASCII码,但是UTF-8的编码规则和ASCII不同,必须要特殊处理ASCII码。 任何编码在底层上都是二进制字节流 ,解码器在获得 1字节的二进制数据时,如何知道这是 ASCII 码,还是 UTF-8编码的高字节或低字节呢?所以 UTF-8 首先要做的是在二进制字节上必须与 ASCII 区分开来,即在这 1字节数据上做标记,通过标记就知道这是 UTF-8编码还是 ASCII码。ASCII是单字节, 2字节以上的数据用UTF-8编码才有意义,否则 1个字节就够用的话就直接用 ASCII了。ASCII码范围是 0 ~ 127, 因此其最高位是0,而2字节以上的UTF-8编码其高字节最高位是1,这样高字节己经可以和ASCII 区分了,那么低字节如何和 ASCII 区分呢?你可能会说,只要 UTF-8 编码中低字节最高位也不为 0 就可以了,即只要是 1 就行 。 其实不然,仅仅最高位为1是区分不了的。因为如果只要求最高位是 1,那么就有可能和高字节混淆,比如二进制 11001101,这是UTF-8的高字节还是低字节?没有办法区分。那么,最不可能成为UTF-8高字节标记位的就是10,我们假设10是高字节的标记位,按照 UTF-8编码规则,说明 UTF-8编码只用了 1字节, 显然这是矛盾的,因为在 UTF-8 中 1 字节的字符用其兼容的 ASCII 码表示,最高位是0,而不是1,因此UTF-8至少要2字节以上才有意义,1字节纯粹是为了兼容 ASCII 码,所以采用 10 作为低字节的标识位才是最合适的。既然标识位10只能出现在低字节的高2位 ,那么反过来说, UTF-8 编码中以10开头的都是低字节。 低字节有了这个特性便具备了校验的能力,比如读取UTF-8编码的高字节后,确保后面的低字节必须以10开头才是正确的UTF-8编码。
结语
我们现在已经知道了,Unicode和UTF-8到底是什么了。并且我们也能够知道,当当前的UTF-8编码是两个字节的时候,实际上,用于存储数据的位数是没有满满的两个字节(16位),而是11位。为啥呢?因为高字节的前三位110是标志位,低字节的前两位10是标志位,因此总共的标志位就有5位,剩余的存储为只有11位了。同理,我们也能通过存储占用的空间大小来反推出UTF-8编码占据多少字节。
希望您对Unicode和UTF-8有了准确地认识了