引言
想必大家之前一定 会被字符编码困惑。ASCII,GB2312,Unicode,GB18030等等,或者说大家遇到过文件乱码问题。那么这一系列的编码到底是什么?他们之间又会有什么区别?又为什么产生乱码问题?
背景
大学都学过计算机相关的基础知识,计算机只能计算二进制数据,因为二进制表示起来最方便。计算机电子元器件表示两个状态很简单,比如高压和低压,对应的就是1和0。如果设计出10种状态,那么计算机的设计会相当复杂。所以现在的计算机都是二进制,在通俗的来讲,就是01构成!那么问题来了。我们人类交流的主要方式是语言,而语言往往是由大量的符号构成的,所以很自然的就会想到使用二进制编码,对应到指定的符号,即一个唯一的编码对应一个唯一的符号。在这里说两个概念;
- 字符集:一堆符号的
集合,里面包含了符号,文字,图形符号,数字,甚至可以是表情包。(对于人的字符集合) - 字符编码:一套
规则。使一个二进制代码对应到一个符号的规则。一串00101010的代码,规则A就可以把他读成:0010 1010(读取两次),而规则B就把他读成:”00101010“
细心的读者可能有所发现,没错,上面的那些ASCII等,都有自己的字符集和字符编码,其中字符编码就一一对应自己字符集内的所有内容
怎么理解…数字到字符的映射呗。
计算机内部在运算的都是数字。但是人不能只看数字,人得看文字,人得看屏幕上输出的文字。所以就得建立一种从数字到文字的映射,在输出的时候根据映射把数字转为文字,这样我们才能看人话。
ASCII码就是这么一套规则,包含了26个英文字母数字标点符号,还有一部分特殊字符(换行符,机箱响一下)的映射规则。
至于说为什么某个字符就是那个编码,这是人为规定的。你要想自己编一套编码完全可以,只是大家已经将ASCII码作为标准了,没人会用你的就是了。如果用你的编码写了东西,那在通用的平台上默认用ASCII码解析,就会映射出不一样的奇怪内容,俗称乱码。
至于说中文怎么办,那就是GBK,Unicode这些在ASCII编码的基础上扩展出来的新编码的事了。
ASCII
当初计算机是在美国流行起来的,所以当他们考虑计算机显示文字的问题时,想到的肯定只有字母。计算机发明之初,没有考虑那么多。作为现代计算机的发源地,当时也只考虑了美国的需求。于是乎,ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)编码便呼之欲出,称之为ASCII编码或者ASCII字符集(叫法不同而已,但是我觉得叫字符集更准确)。只需要128个字符,如果用数字一一对应,一共只需7位二进制数字。计算机存储的最小单位是byte,即8位。ASCII字符集把最高位设置为0,用剩下的7位来表示字符。
下图便是ASCII表(数字代码和符号的对应关系)
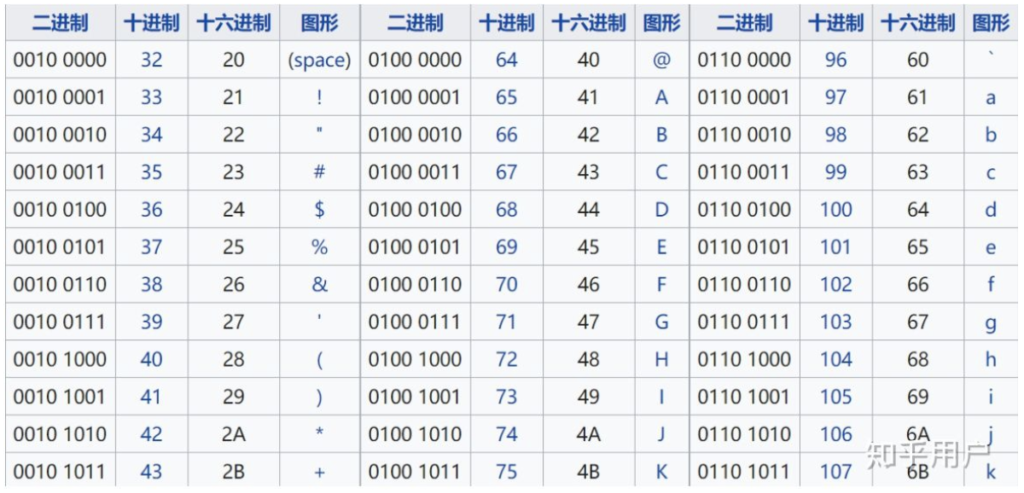
具体规则:在ASCII中规定:一个字节所对应一个符号。在计算机中,一个字节包含8位,一个字节所能表示的不同状态也只有:256个(
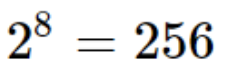
)>) 。就像上图:符号A,所对应的数字编码为:0100 0001。
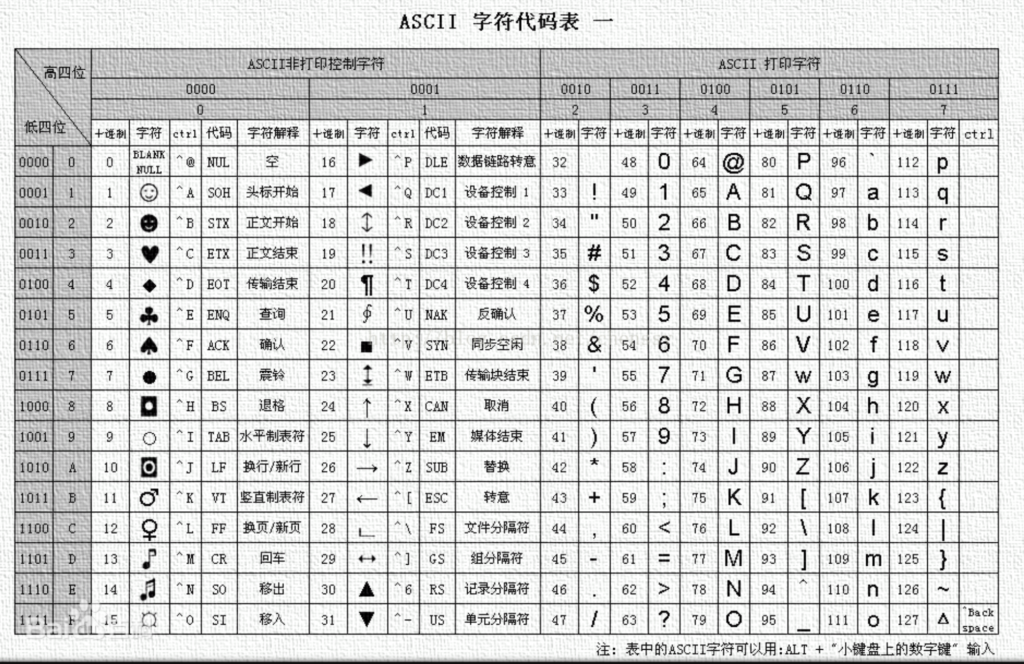
但是需要注意的是在ASCII字符集中,只有128个符号,因此ASCII内,128的对应关系。其中前32个符号,是非显示字符(计算机显示)。
图中把ASCII字符集分为了两大部分,打印和非打印。打印部分好解释,就是会输出在显示设备上的,可以看看我们的键盘上,一般也都会有这些字符。非打印部分更多的是控制目的。比如NUL表示空字符,\n表示换行,\r表示回车等。
对于美国来说,ASCII是够用了,但是其他很多国家显然就不够用了。下面简单说说一些常见的。ISO 8859-1和Windows-1252。这两个都加入了西欧字符,两者基本一样,ISO 8859-1号称是用于西欧国家的标准字符集,但是Windows-1252更常用些。
中文的第一个标准字符集是GB2312,有大约7000个汉字和一些罕用词和繁体字。其使用两个字节表示汉字。GBK建立在GB2312的基础上,并向下兼容。共计包含了21000个汉字,其中包含了繁体字。GB18030进一步增强了GBK,同样可以向下兼容,共包含了76000个字符,其中有很多少数民族字符,以及中日韩统一字符。但是两个字节已经表示不了GB18030中的所有字符了,GB18030使用了长编码,有的字符是两个字节,有的是四个字节。两个字节的编码中,表示范围和GBK一样。除了以上表示中文的字符集外,还有个Big5,是针对繁体字的,广泛应用于湾湾省和香港那边。
前面说了这么多,是不是觉得很麻烦。不同的国家地区,还得用不用的字符集。前面讲到的所有字符集统称为非Unicode字符集。为了解决每个国家不同字符集间的不兼容现状,便有了Unicode字符集。它做了一件事,就是给世界上所有字符都分配了一个唯一的数字编号,有110多万,但大部分都在0x0000~0xFFFF之间,即65536个。
3.非ASCII编码
3.1 GBXXXX字符集&编码
聪明的各位可能就就要问了,欧洲,美洲都把256个对应关系都用光了,我们大中国怎么办?我们博大精深的文字如何表示?特么我们汉字有几万个,常用的就有几千个,没有两个字节根本交不了货。于是勤劳勇敢的中国人民就破天荒的用了两个字节来表示中文。整出一套GBK。为了现实我中华民族兼容并蓄,我们兼容了ASCII编码。
GBK编码规定,计算机不能在每次都只读一个字节那么死板了,你要先看看第一位是不是为0,要是为0 的话,就当作ASCII码来读入一个字节,不然的话就读入两个字节。
GB开头的就是我们中国的字符编码。GB就是国标的首字母大写。下面的图是2312的对应规则。

具体规则:
在GB2312中规定:两个字节所对应一个符号。
为什么ASCII一个字节表示,而GB2312用两个符号表示?
亲,因为咱们的字多呀!两个字节可以有65536个对应状态
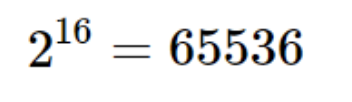
3.2 Unicode编码
可能又要有人问了,不同国家的字符编码不同,那么如何保证信息的准确性?如果我在中国写好的文档,跑到美国去,那我的文档岂不是要乱了?其实在Unicode没有出世之前的确是这个样子的。随着互联网的出现,全世界的人们都在用自己的语言去共享着信息,如果所使用编码不统一,势必会产生乱码的情况的。
那么只有一个解决方式:将世界上所有的文字都去遵循同一种编码方式。这个方法看样子是不是很难实现?但是他已经被Unicode去实现了,所以Unicode是一个很伟大的编码方式;
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
说人话就是:将世界上所有的符号都纳入其中,并且都有与之对应的关系;
(最新的Unicode14.0编码规范要在2021年3月发布,由于疫情故推迟到2021年9月发表。)
3.3 UTF-8编码
在Unicode值得注意的是:Unicode仅仅规范了符号的编码方式,但是对于存储的方式并没有对此说明。
因为有的符号仅需要一个字节,有的需要多个字节。比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。如果全都以:四个字节去存储,由于较小值的编码点一般使用频率较高,直接使用Unicode编码效率低下,大量浪费内存空间。UTF-8就是来解决这个问题的。即解决Unicode存储问题。(后面的8就是以8位为单元进行编码)
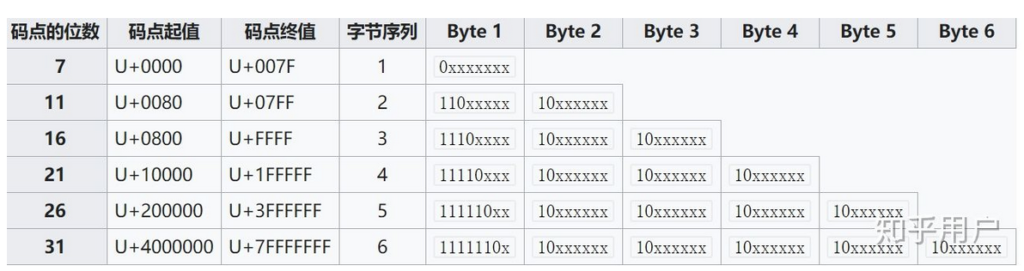
utf-8为了节省资源,采用变长编码,编码长度从1个字节到6个字节不等
UTF-8的编码规范:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。 2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。 3)如果开头是0,表示只有1个字节;否则,头一个字节的第一个0前面多少个1就表示有多少个字节
4.乱码的由来
看到这里,为什么乱码相信你肯定知道了。无非就是使用了不同的字符集,导致解析错误。那么该怎么恢复乱码呢?如果你知道原编码方式最好,直接切换成对应的字符集即可。比如在一些可以切换编码方式的文本编辑器里、HTML的原信息设置、IDE的设置等。
但是如果不知道的话,也没什么太好的方式,只能一个个尝试了。我们可以写个简单的小程序,通过遍历常见字符集,来试着解析出乱码的原有格式。以Java为例:String newStr = new String(str.getBytes(charsets[i]),charsets[j])。这句代码的意思就是:假设乱码str原来是charsets[j]编码的,被错误解析为charsets[i]编码的。在尝试前,切记要对原文件做备份,因为多次错误的解析和转换,可能很难再恢复成正常的字符了。
5.结束
至此,计算机表示语言的方式(即编码规范)基本大势已定,绝大多数都是Unicode编码,UTF-8存储。从此以后互联时代得到了飞速发展。全世界人们尽管语言不同,但是表示语言的方式完全统一!使得全球互联,世界互惠,人们互通!故此致敬各位前辈在字符编码上所付出的努力!