Fluentd是一个开源的通用日志采集和分发系统,可以从多个数据源采集日志,并将日志过滤和加工后分发到多种存储和处理系统。
套一句广告语:Fluentd不生产日志,Fluentd只是日志的搬运工。~_~
先来看一张官网介绍的图片:
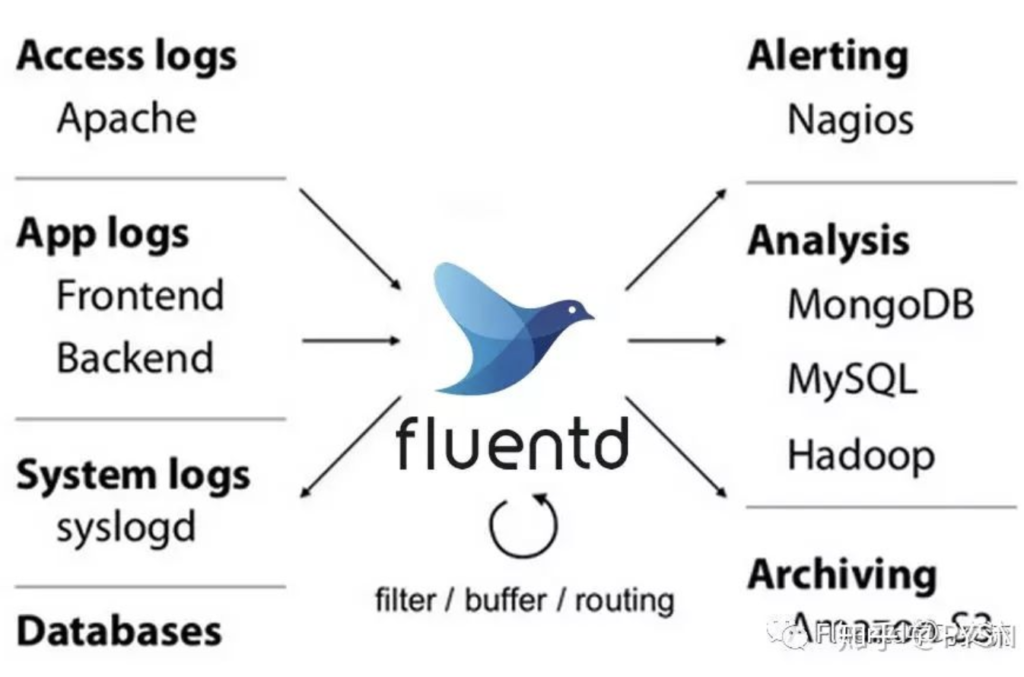
从图中可以看出,Fluentd居于日志采集流程的中间层。
它可以从Apache/Nginx等广泛应用的系统、数据库、自定义系统中采集日志,数据进入Fluentd后可根据配置进行过滤、修改、缓存,最终分发到各种后端系统中。这些后端系统包括告警系统(Nagios)、分析系统(MongoDB、MySQL、Hadoop、ElasticSearch)、存储系统(Amazon S3)等。
说白了,Fluentd就是把通常的日志采集-缓存-分发-存储流程提炼出来,用户只需要考虑业务数据,至于数据的传输、容错等过程细节都交给Fluentd来做。所谓通用中间件不都是这样一个逻辑吗?
为了统一处理各种日志,Fluentd把JSON作为内部数据格式,流入和流出的数据都是JSON格式。由于JSON是一种通用的跨平台的数据格式,这给现有系统的改造带来很大便利。
由于对日志业务流程做了抽象,为了能支持各种日志,Fluentd将各采集分发步骤插件化,通过在各个步骤接入合适的插件来处理对应的业务数据。
Fluentd内置了常用的插件,比如in_tail、in_http、out_file、out_mongo等,开源社区也贡献了更丰富的插件。通过组合各种插件,我们能够轻松搭建起自己的日志采集系统。
Fluentd使用C作为开发语言,其插件系统的开发使用到了Ruby。C保证了系统的高效,Ruby给用户提供了一个灵活使用插件的途径。笔者对Ruby不是很熟,为什么不用Lua呢?
现在你应该知道Fluentd是个什么东东了吧。