转载:https://captainbed.vip/1-2-1/
我们需要弄懂的第一步就是如何将数据输入到神经网络中。例如,在我们百度的新产品“小度智能屏”中,是如何将麦克风采集到的音频数据输入到神经网络中的;小度智能屏还能根据人脸来判断年龄从而自动切换成人和儿童模式,那它又是如何将摄像头采集到的人脸数据输入到神经网络中的。(稍微植入下广告,小度智能屏是我们精心研发的一款新产品,它功能非常强大,好玩又实用,很值得拥有!)
下面我拿识别女优的例子来给大家介绍如何将女优的图片数据输入到神经网络中。
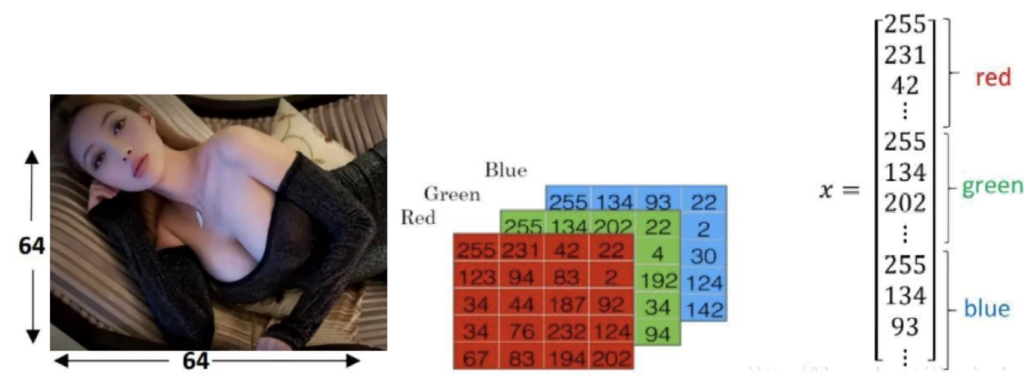
此例中,待输入的数据是一张图像。为了存储图像,计算机要存储三个独立的矩阵(矩阵可以理解成二维数组,后面的教程会给大家详细讲解),这三个矩阵分别与此图像的红色、绿色和蓝色相对应(世界上的所有颜色都可以通过红绿蓝三种颜色调配出来)。如果图像的大小是64 * 64个像素(一个像素就是一个颜色点,一个颜色点由红绿蓝三个值来表示,例如,红绿蓝为255,255,255,那么这个颜色点就是白色),所以3个64 * 64大小的矩阵在计算机中就代表了这张图像,矩阵里面的数值就对应于图像的红绿蓝强度值。上图中只画了个5 * 4的矩阵,而不是64 * 64,为什么呢?因为没有必要,搞复杂了反而不易于理解。
为了更加方便后面的处理,我们一般把上面那3个矩阵转化成1个向量x(向量可以理解成1 * n或n * 1的数组,前者为行向量,后者为列向量,向量也会在后面的文章专门讲解)。那么这个向量x的总维数就是64 * 64 * 3,结果是12288。在人工智能领域中,每一个输入到神经网络的数据都被叫做一个特征,那么上面的这张图像中就有12288个特征。这个12288维的向量也被叫做特征向量。神经网络接收这个特征向量x作为输入,并进行预测,然后给出相应的结果。
对于不同的应用,需要识别的对象不同,有些是语音有些是图像有些是传感器数据,但是它们在计算机中都有对应的数字表示形式,通常我们会把它们转化成一个特征向量,然后将其输入到神经网络中。