转载:小红书 AI产品赵哥
前言🔖
经常玩 Agent 的朋友们都有体会:Agent 技能一多就变傻?对,我也踩过这个坑……
事情是这样的,我给我的 Agent 配了十几个技能,一开始它贼聪明,说分析数据就分析数据,说写报告就写报告,指哪打哪。我当时真觉得自己离目标不远了。
然后。。。就翻车了。
技能加到七八十个之后,它开始乱来。让它查个数据,它跑去调用写作技能;明明旁边就放着一个完美能用的工具,它装没看见,跟我说做不到。我熬了好几个大通宵去调 prompt,屁用没有。
后来我才搞明白一个事:Agent 没变笨。是技能太多了,导致 Agent 迷路了。
- 十几个技能的时候,它就是做选择题,瞄一眼就知道该拿哪个。
- 上百个技能的时候,它是在一个巨大的仓库里翻一个自己都记不清长什么样的东西。这已经不是选择题了,是检索问题。
而且这事儿在面试里也常被问到:技能太多怎么保命中率?
我试了很多办法,踩了很多坑,最后总结了在不同情况下的 4 种有效的方法,分享给大家:
一、方法一:给技能写一份 “求职简历”,而不是 “功能说明”🔖
很多开发者在提升命中率时,都走错了方向。他们把 90% 的精力都花在了优化每个技能内部的执行逻辑和 Prompt 上,却忽略了最最关键的一环 ——技能的 name 和 description。
怎么说呢?这就像是一个公司的 HR,手上有 100 份简历。如果你只看简历的正文,那得累死。你肯定会先快速浏览每份简历的 “姓名” 和 “求职意向 / 核心优势”,对吧?
对于 AI Agent 来说,技能的名称和描述,就是这份简历的 “姓名” 和 “求职意向”。
这里要引入 Anthropic 提出的核心思想,叫做渐进式披露(Progressive Disclosure)。它的意思是,AI 在选择技能时,并不会傻了吧唧地把上百个技能的完整代码和 Prompt 全部读一遍(那样上下文窗口早就宇宙大爆炸了)。它的工作流程是:
- 第一轮筛选(浏览简历标题):AI 首先只读取所有技能的名称和描述,形成一个 “候选清单”。
- 第二轮精读(详读简历内容):然后,它从这个候选清单里,挑出几个最有可能的,再加载它们的完整内容进行最终判断。
所以你看,如果你的技能描述写得一塌糊涂,它在第一轮筛选时就会被 pass 掉,无论你内部的 Prompt 写得多么优秀,AI 根本没机会看到!
【错误示范 & 痛点分析】
很多人的描述都是功能性的,非常模糊,比如:
name: "data_analyzer" description: "一个数据分析助手。" name: "ppt_generator" description: "用于生成PPT。" name: "code_expert" description: "代码处理专家。"
当你只有三五个技能时,这没问题。但当你有 10 个不同的数据分析技能(一个负责清洗、一个负责可视化、一个负责建模型),20 个不同的代码技能时,AI 看到这些描述,内心是崩溃的:“大哥,都是专家,我到底该请哪位啊?!”
【正确做法 & 核心心法】
💡 不要只写这个技能 “是什么”,要重点写 “什么时候应该用它”。把功能描述,升级为场景描述。
因为 AI 在做技能路由时,本质上是在做用户意图和技能描述之间的语义匹配。你的场景描述得越具体、越丰富,语义的钩子就越多,就越容易被 AI 精准地钓起来。
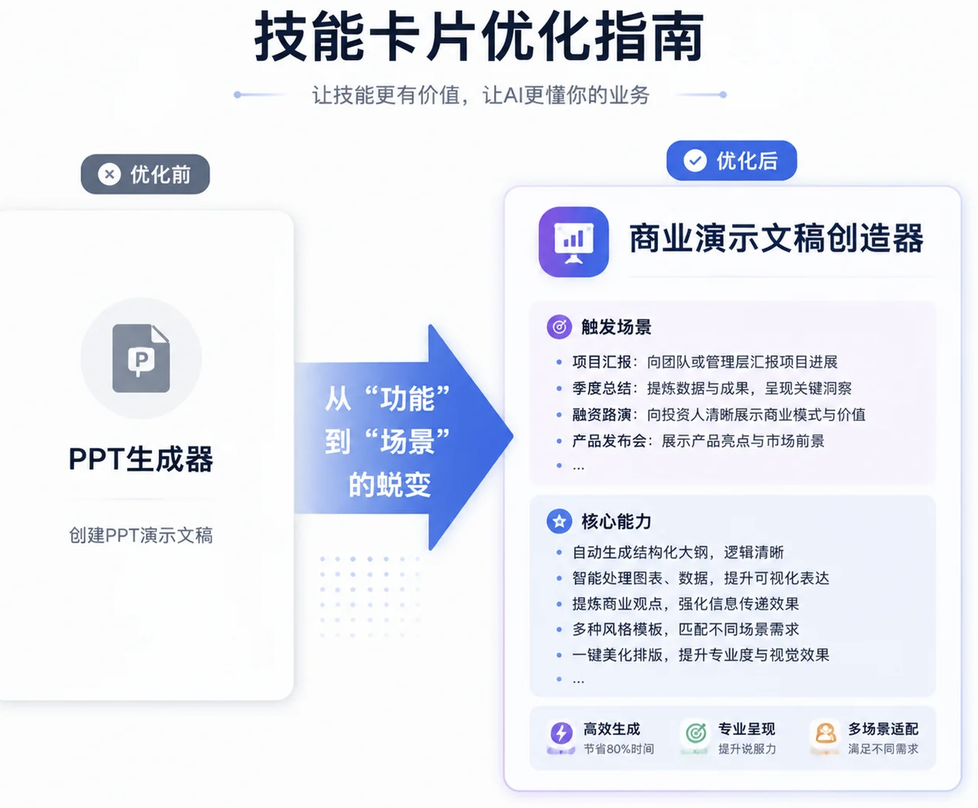
【优化前后对比】
优化前 (Before): name: "ppt_generator" description: "负责生成 PPT。" 优化后 (After) name: "presentation_creator_for_business_scenarios" description: "当用户要求制作商业演示文稿、项目汇报材料、季度总结、产品发布会幻灯片或融资路演 PPT 时,使用此技能。它擅长处理包含图表、数据和商业观点的结构化内容。"
再来一个例子:
优化前 (Before) name: "sql_writer" description: "SQL 编写工具。" 优化后 (After) name: "database_query_generator_sql" description: "当用户需要从数据库中查询、筛选、聚合或提取数据时,使用此技能来生成 SQL 查询语句。例如:‘帮我查一下上个月销量最高的前 10 个商品’或‘统计每个部门的平均工资’。"
看到了吗?优化后的描述,包含了大量的触发关键词(汇报材料、融资路演、查询、筛选、统计)和具体的例子。当用户的提问中包含了这些词或相似的语义时,这个技能被命中的概率就会指数级提升。
另外多说一嘴,这个想不想传统的 SEO 做的事情?其实底层逻辑是一样的。
二、方法二:告别 “大平层”,给你的技能们建一棵 “树”🔖
如果说第一招是微观优化,那么第二招就是从宏观改革。
想象一下,你家里的 100 本书,如果全部堆在地板上,每次找书都得一本本翻,是不是很痛苦?但如果你买个书架,按照 “文学、历史、科技、艺术” 分好类,再在每个分类下按作者或书名排序,找书的效率是不是瞬间就上去了?
技能分层(Skill Layering),或者叫构建技能树(Skill Tree),就是为你的 Agent 建立一个这样的书架。
【错误示范 & 痛点分析】
很多团队在开发 Agent 时,习惯于把所有技能都平铺在一个列表里。这意味着,AI 每次接到任务,都必须在上百个技能中进行全量扫描。这个搜索空间太大了!AI 很容易就选错了方向。
【正确做法 & 核心心法】
不要让 AI 一次性面对所有选项,而是通过分层结构,引导它进行渐进式决策。
你需要像图书管理员一样,为你的技能建立一个层次化的分类体系。
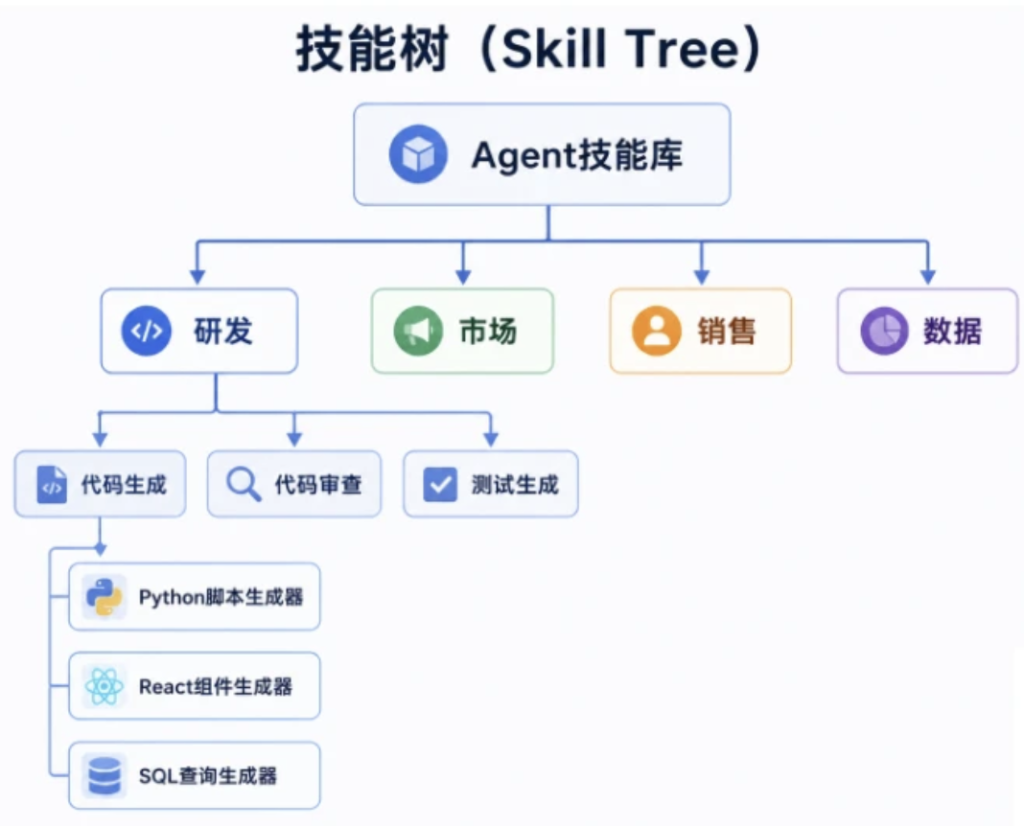
【构建技能树的步骤】
- 定义顶层分类(Level 1):根据你 Agent 的核心功能域,定义几个大的类别。这通常与公司的部门或业务线相对应。
- 例如:研发 (Engineering)、市场 (Marketing)、销售 (Sales)、数据科学 (DataScience)。
- 定义子分类 (Level 2):在每个大类下,再进行更细致的划分。
- 在研发下,可以有:代码生成 (CodeGeneration)、代码审查 (CodeReview)、测试用例生成 (TestGeneration)、部署运维 (DevOps)。
- 在市场下,可以有:社交媒体文案 (SocialMediaCopy)、广告活动策划 (CampaignPlanning)、市场调研报告 (MarketResearch)。
- 挂载具体技能 (Level 3):将你具体的技能,挂载到最底层的分类下。
- 在代码生成下,可以有:python_fastapi_generator、react_component_builder、dockerfile_creator。
【AI 的决策路径变化】
- 分层前:用户说:“帮我写个 Python 后端接口”。AI 需要在 100 个技能里大海捞针。
- 分层后:用户说:“帮我写个 Python 后端接口”。
- a. AI 首先判断,这个任务属于哪个大类?“后端接口”→ 研发 (Engineering)。搜索范围从 100 缩小到 30。
- b. 在研发大类下,它再判断属于哪个子类?“写接口”→ 代码生成 (CodeGeneration)。搜索范围从 30 缩小到 5。
- c. 最后,在代码生成的 5 个技能里,它看到了 python_fastapi_generator,描述是 “用于快速生成基于 FastAPI 框架的 Python 后端接口骨架”,命中!命中!命中!
这个过程,就像你在购物网站上找东西一样:“电子产品 → 手机 → iPhone”,而不是在一开始就面对网站上所有的商品。
💡 很多大型的、企业级的 Agent 系统,内部都采用了类似的分层路由机制,这几乎是系统扩展性的命脉所在。
三、方法三:明确告诉 AI “什么不能做”🔖
我们教孩子东西时,不仅会告诉他 “可以做什么”(比如,可以玩积木),也会明确警告他 “不能做什么”(比如,不能触摸电源插座)。
给 AI 定义技能时,也需要这种 “负向引导”。除了告诉它什么时候该用这个技能,同样重要的是,要告诉它什么时候不该用。
这就是增加负样本描述(Negative Sample Description)。
【错误示范 & 痛点分析】
很多误触发,都发生在语义相关但不完全正确的灰色地带。
比如你有一个技能:
- name: “sql_query_generator”
- description: “用于生成 SQL 查询语句,帮你从数据库里查数据。”
当用户说:“帮我优化一下数据库性能” 或者 “设计一下用户表的结构” 时,AI 可能会因为看到了 “数据库”、“SQL” 这些关键词,就错误地触发了这个 sql_query_generator 技能。结果自然是文不对题,胡说八道。
【正确做法 & 核心心法】
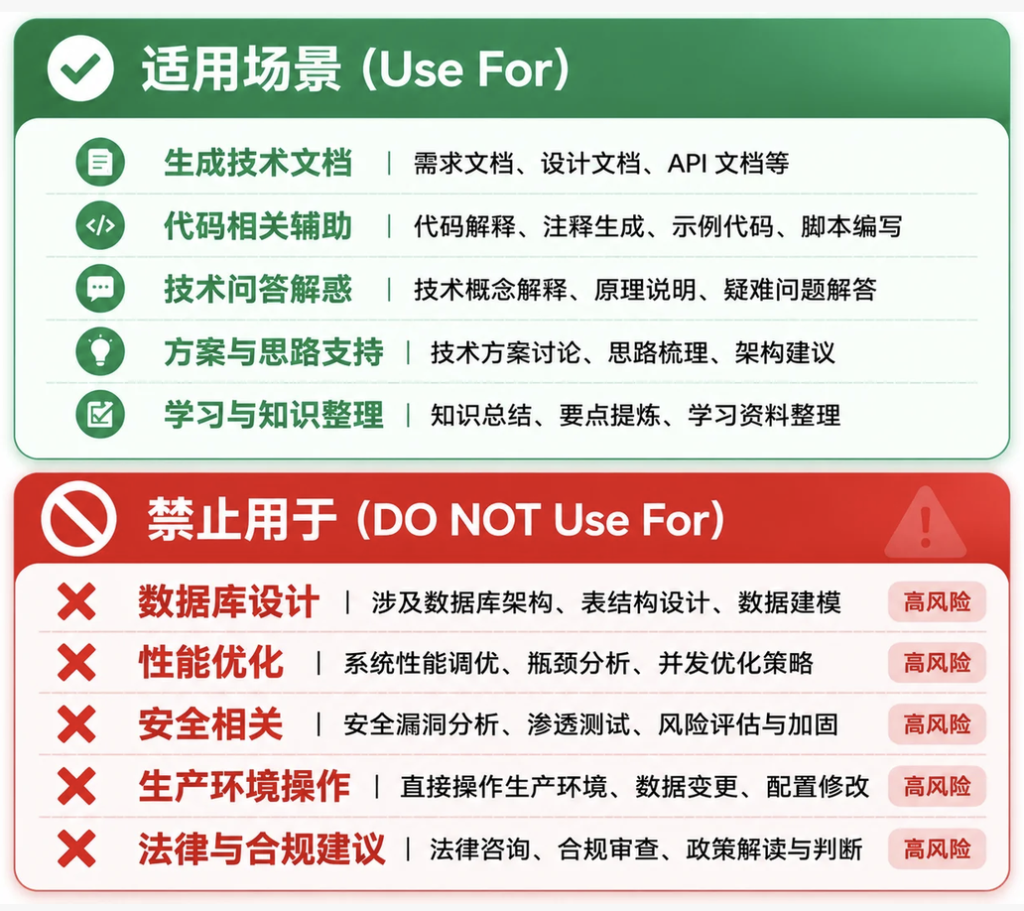
在技能描述中,专门开辟一个不适用场景(When NOT to Use)或能力边界(Scope Limitations)的区域,用明确的语言为技能划定能力边界。
【优化前后对比】
优化前 (Before):
- name: “frontend_code_generator”
- description: “一个前端代码生成工具,可以帮你快速构建页面。”
优化后 (After):
- name: “react_component_generator”
- description: “用于生成独立的、可复用的 React 组件代码。适用于构建 UI 界面中的按钮、表单、弹窗等元素。”
- 不适用场景 (When NOT to Use):
- 不负责后端接口开发或数据库交互。
- 不处理项目的构建配置或部署流程(如 Webpack,Vite 配置)。
- 不进行端到端的完整页面开发,只生成单个组件。
通过这种方式,你等于给 AI 的决策路径上设置了几个鲜明的红色警示牌。当用户任务涉及到 “后端”、“数据库”、“部署” 时,AI 在评估这个技能时,会因为这些负向描述而大大降低其匹配分数,从而避免了误触。
社区里许多高质量的开源 Skill 项目,都已经开始将 When NOT to Use 作为标准配置的一部分,因为它对于减少误报、提升技能调用的精准度,效果立竿见影。
四、方法四:引入多轮筛选,召回与重排🔖
当你的技能库真的达到成百上千这个量级时,即使做了前三步优化,单靠一个大模型直接从头选到尾,仍然会非常吃力,而且成本高、速度慢。
这就好比一个大型企业招聘,不可能让 CEO 亲自去筛选成千上万份简历。更合理的流程是:
- 初筛(召回):由 HR 团队(或者一个快速的算法)先从简历池里,通过关键词、学历等硬性指标,快速筛选出 100 份看起来还不错的简历。
- 精选(重排):再由业务部门的资深经理,来仔细阅读这 100 份简历,从中挑出 10 份最合适的,安排面试。
- 终面(决策):最后,由 CEO 或核心高管,面试这 10 个人,做出最终的录用决策。
我们可以把这个思路,照搬到 Agent 的技能选择中来。这就是 ** 召回与重排(Recall and Rerank)** 策略。
【核心思想】
💡 不要让昂贵且强大的大语言模型去做大海捞针的粗活,让它只专注于优中选优的精细活。
【工作流程详解】
- 1. 第一步:快速召回 (Recall)
- 目标:从全部(比如 500 个)技能中,快速、低成本地筛选出一个较小的候选集(比如 Top 10)。
- 方法:这一步不使用昂贵的大模型。而是用更高效的检索技术。
- 关键词检索 (Keyword Search):最简单的方法。基于用户的提问,在所有技能的描述中进行文本匹配,找出包含相关关键词的技能。
- 向量检索 (Vector Search / Embedding):更高级、更主流的方法。你需要提前把所有技能的描述,通过一个模型(不一定是大模型,很多小模型效果就很好)转换成一串串数字,也就是向量 (Embedding)。这些向量代表了描述的语义。当用户提问时,也把他的问题转换成向量,然后在向量空间中,寻找与问题向量距离最近的 10 个技能向量。
- 结果:一个包含 10 个 “嫌疑最大” 的技能的小列表。
- 2. 第二步:精准重排 (Rerank)
- 目标:在这 10 个候选技能中,做出最终的、最准确的选择。
- 方法:现在,终于轮到我们强大的专家 —— 大语言模型登场了。
- 你把用户的原始问题,和这 10 个候选技能的详细描述(甚至可以包含完整的 Prompt),一起打包塞给大模型,然后向它提问:“根据用户的需求,请从以下 10 个工具中,选择最合适的一个。如果都不合适,请回答‘无’。”
- 结果:大模型凭借其强大的推理能力,在这 10 个高度相关的选项中,做出最精准的判断。
【价值与优势】
- 效率和成本:98% 的粗筛工作由高效、廉价的检索算法完成。昂贵的大模型调用,只发生在最后一步,大大降低了单次决策的成本和延迟。
- 准确性:大模型不再被海量无关信息干扰,可以集中算力去分析少数几个最相关的选项,决策质量自然更高。
实际上,这个 “召回 + 重排” 的思路,和我们常说的 RAG(检索增强生成)技术是同出一源的。当你把技能库看作一个 “知识库” 时,选择技能的过程,就是一个对 “知识” 进行检索和利用的过程。
💡 当你的 Agent 系统发展到一定规模,你的技能路由模块(Skill Router)本身,就已经演变成了一套复杂的、迷你的检索引擎了。