转载:小红书 AI产品赵哥
前言🔖
各位探索 AI 的小伙伴们,你有没有过这种经历:
- 在购物软件搜了一下机械键盘,打开短视频全是键盘测评;
- 你问 AI 写一首关于孤独的诗,它张口就来 “寂寥”、”阑珊”;
- 听歌软件里多放了几首周杰伦,它就开始推林俊杰和五月天,还挺准。
这时候你肯定想知道:它怎么知道我在想什么?怎么理解 “机械键盘” 和 “普通键盘” 的区别?怎么判断 “国王” 和 “王后” 是一伙的,而 “国王” 和 “苹果” 不是?
今天给大家介绍一个概念 —— Embedding(嵌入)。上面的这些问题,都和这个概念有关!
今儿个咱不聊虚的,就用几个你能听懂的比喻,聊聊 AI 是怎么把我们这个有意义的世界,翻译成它自己的语言的。
好了,大家准备好了吗?咱发车了!
一、AI 其实是个文盲!🔖
在聊 Embedding 之前,我们必须先了解一个现实:你的电脑,无论多贵,它本质上都是个文盲。
它不认识 “爱”,也不认识 “恨”;它不知道 “猫” 和 “狗” 的区别,更不理解 “天空为什么是蓝色的”。在计算机的底层世界里,只有 0 和 1。它唯一能做的,就是进行数学运算。
所以,AI 面临的第一个天大的难题就是:如何把人类世界中充满意义的万事万物(特别是文字),转换成计算机能够处理的数字?
这个过程,我们称之为表示(Representation)。在 Embedding 出现之前,前辈们进行过很多艰苦但又有点笨拙的尝试。
🔹1.1 笨方法一:编号法
最直观的想法,就是给每个词编个号,就像字典一样。比如,我们有一本很小的词典:
{"国王": 1, "王后": 2, "男人": 3, "女人": 4, "苹果": 5, "橘子": 6}。
这样,“国王” 就是 1,“王后” 就是 2。看起来问题解决了?
不,问题才刚刚开始。
这种编号,在计算机眼里,2-1=1,所以 “王后” 减去 “国王” 等于 “国王”?6-5=1,所以 “橘子” 减去 “苹果” 也等于 “国王”?这完全是胡闹。这些编号之间没有任何数学关系,AI 学不到任何东西。
🔹1.2 笨方法二:One-Hot 编码(独热编码)
为了解决上面那个问题,科学家们想出了一个更聪明的办法:One-Hot 编码。
这个方法很像我们教室里点名。假设我们班(词典)里有 10000 个同学(单词)。
要表示 “国王” 这个词,我们就造一个有 10000 个位置的点名册(一个向量)。然后,在代表 “国王” 的那个位置(比如第 58 号位)打上一个 “1”(到!),其他所有 9999 个位置都写上 “0”(没来)。
- “国王” 的编码可能是:[0, 0, …, 1, …, 0, 0](在第 58 位是 1)
- “王后” 的编码可能是:[0, 0, …, 1, …, 0, 0](在第 99 位是 1)
- “苹果” 的编码可能是:[0, 1, …, 0, …, 0, 0](在第 2 位是 1)
One-Hot 编码解决了编号法那个 “数字大小没意义” 的问题,因为现在每个词都是平等的。但它却带来了两个更致命的问题:
问题 1:维度诅咒与内存爆炸
一个常用语料库,有 10 万个词都算少的。那意味着每个词的 One-Hot 向量,都是一个 10 万维的向量!这在计算机里存储和计算,简直是天文数字,内存分分钟爆炸。而且,这个向量里只有一个 1,其他全是 0,极其稀疏,效率极低。
问题 2:语义鸿沟
这是最要命的。在数学上,One-Hot 编码得到的任意两个不同词的向量,都是相互 ** 正交(Orthogonal)** 的。
正交你可以理解为互相垂直。这意味着,在 AI 看来,“国王” 和 “王后” 之间的关系,跟 “国王” 和 “拖拉机” 之间的关系,没有任何区别!它们都是完全不相关的。
这还咋玩?AI 连最基本的 “猫和狗都是动物,所以比较像” 都理解不了,后续的一切智能都无从谈起。
所以,我们需要一种新的方法,既能把词变成数字,又能把词与词之间的语义关系也编码进去。
这时,Embedding,闪亮登场。
二、Embedding:给每个词一个语义坐标🔖
Embedding 的思想,彻底抛弃了 One-Hot 那种 “是不是这个词” 的孤立思维,转向了一种全新的思路:
我们不用一个孤零零的 “1” 来表示一个词,而是用一组有意义的数字来描述这个词的属性和内涵。
什么意思呢?我们来构建一个比喻。
想象一个巨大的、多维的语义空间,就像一个宇宙。我们世界上的每一个词,都是这个宇宙中的一颗星星。而 Embedding,就是给每个词(每颗星星)分配一个独一无二的宇宙坐标。这个坐标不是一个单独的数字,而是一个由几百个数字组成的向量(Vector)。
比如,一个 300 维的 Embedding,就意味着每个词的坐标都是一个包含 300 个数字的列表,如:
“国王” = [0.26, -0.41, 0.55, …, 0.99](共 300 个数字)
这个向量(一组数字)有什么特别之处呢?
- 它不再是稀疏的,而是稠密的(Dense)。每个数字都有意义,不再是海量的 0。300 维相对于 10 万维,极大地节省了空间,解决了维度诅咒。
- 最最神奇的是:这个坐标本身,就编码了词的语义!
- 语义相似的词,它们在这个空间中的坐标就彼此靠近。比如,“国王” 和 “王后” 的坐标点会离得很近;“苹果” 和 “橘子” 的坐标点也会离得很近。
- 语义不相关的词,它们的坐标就相距遥远。比如,“国王” 和 “苹果” 的坐标点,可能就隔了十万八千里。
现在,AI 终于开窍了!它不需要认识字,只需要计算两个词 Embedding 向量之间的空间距离(比如欧氏距离或余弦相似度),就能判断出它们的语义有多相似!
这,就是 Embedding 的魔力。它把一个复杂的语言学问题(词义相似度),巧妙地转化成了一个简单的数学问题(向量空间距离计算)。
三、看一个神奇的结论:“国王 – 男人 + 女人 = 王后”🔖
上面的内容还只是理论,接下来这个例子,就是 Embedding 最著名的例子,它能让你更深刻的理解词向量与空间距离。
当科学家们训练出了早期的词嵌入模型(如 Word2Vec)后,他们惊奇地发现,这些 Embedding 向量之间,居然可以进行有意义的数学运算!
最经典的例子就是:
Vector (“国王”) – Vector (“男人”) + Vector (“女人”) = ?
我们来拆解一下这个运算在 “语义空间” 里发生了什么:
- Vector (“国王”) – Vector (“男人”):
- 在我们的语义空间里,从 “男人” 这个点指向 “国王” 这个点,可以画一个箭头(向量)。这个箭头代表了什么语义呢?它可能代表了皇室属性或者权力概念。
- … + Vector (“女人”):
- 现在,我们把上面得到的那个代表 “皇室属性” 的箭头,平移到 “女人” 这个点的起始位置。
- 从 “女人” 这个点出发,沿着这个 “皇室属性” 箭头的方向和长度,我们会到达一个新的坐标点。
你猜,这个新坐标点附近,是哪个词?
答案是:王后(Queen)
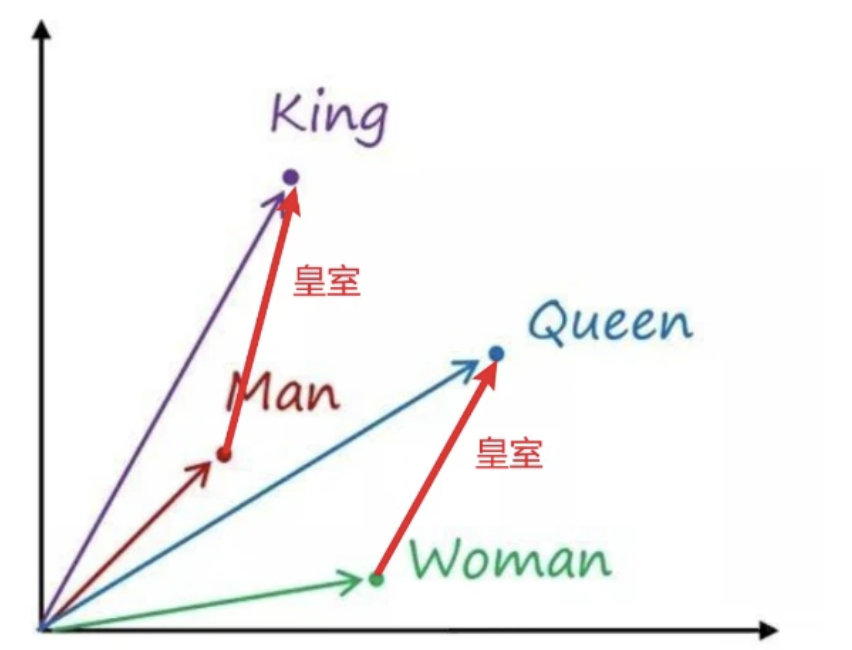
这个结果震撼了整个 AI 界。这意味着,Embedding 不仅学到了词的相似性,更学到了词与词之间复杂的、类比性的关系!
同样的,你还可以做很多有趣的运算:
- Vector (“北京”) – Vector (“中国”) + Vector (“法国”) ≈ Vector (“巴黎”)(首都关系)
- Vector (“烤鸭”) – Vector (“北京”) + Vector (“南京”) ≈ Vector (“盐水鸭”)(特色关系)
Embedding 就像一张被施了魔法的语义地图,它把我们语言中那些微妙的、抽象的逻辑关系,都用精准的几何关系给描绘了出来。
四、揭秘 Embedding 的训练过程🔖
聊到这,你是不是要问:这个语义地图,到底是怎么画出来的?AI 是怎么知道该把 “国王” 放在哪儿,“苹果” 又放在哪儿的?
好问题!
这背后的思想,源于咱们中国老祖宗的智慧 —— “物以类聚,人以群分”。在语言学里,这句话被总结为 “一个词的意义,由它周围的词来定义(You shall know a word by the company it keeps)”。
这不难理解,当我说:“我今天吃了一个很甜的______。”
这个空格里,你很可能会填 “苹果”、“香蕉”、“西瓜”,但你绝对不会填 “拖拉机” 或者 “椅子”。
💡这里有一个非常朴素的认知:经常出现在相似上下文语境中的词,它们的语义也应该是相似的。
基于这个朴素而强大的思想,科学家们设计了训练 Embedding 的算法,其中最著名的就是 Word2Vec 模型家族。它的训练过程,就像是让 AI 做一个大规模的完形填空游戏。
主要有两种玩法:
🔹4.1 玩法一:CBOW (Continuous Bag-of-Words)【根据上下文猜中间的词】
- 我们从海量的文本(比如整本维基百科)里,挖掉一个词,把这个词的上下文交给 AI。
比如,句子是“今天天气很好,我们去公园散步吧”,我们挖掉“公园”。 - 我们把上下文 [“今天”, “天气”, “很好”, “我们”, “去”, “散步”, “吧”] 交给一个简单的神经网络。
- 这个神经网络的任务就是:猜出中间被挖掉的词最有可能是“公园”。
- 一开始,网络里的所有词的 Embedding 都是随机的、乱七八糟的。它肯定猜不对。
- 但没关系,我们告诉它正确答案是“公园”,然后用一种叫做反向传播的算法,让它微调一下所有输入词的 Embedding 向量,使得这一次的猜测结果能更接近“公园”一点点。
- 重复这个过程亿万次!用不同的句子,挖不同的词。
慢慢地,这个神经网络为了能更准确地完成“猜词”任务,就不得不被迫学会:必须把那些可以放在相似上下文里的词(比如“公园”和“广场”,“公司”和“单位”)的 Embedding 向量,调整得越来越相似。
🔹4.2 玩法二:Skip-gram【根据中间的词猜上下文】
这是反过来的玩法。
- 我们给 AI 一个词,比如 “公园”。
- 让 AI 去猜测它的上下文里,最可能出现哪些词。它可能会猜 “散步”、“孩子”、“长椅” 等等。
- 同样,一开始它也猜不对。我们把正确的上下文告诉它,让它去微调 “公园” 这个词的 Embedding,以及上下文词的 Embedding。
- 重复亿万次之后,它同样也学会了那张语义地图。
一个非常重要的洞察是:我们训练这个神经网络的最终目的,并不是真的要它去玩这个完形填空游戏。这个游戏只是一个幌子,一个训练任务而已。
我们真正想要的,是这个神经网络在训练过程中,为了完成任务而被迫学习到的那一层权重参数 —— 也就是包含了所有词的语义信息的 Embedding 向量!
这个过程,就叫做自监督学习(Self-supervised Learning),因为它的学习材料(标签)都来自于数据本身,不需要我们去人工标注。
五、万物皆可 Embedding!就问你牛不牛?🔖
咱聊到这儿,你可能觉得 Embedding 就是用来处理文字的。
那你可太小看 Embedding 了。它的核心思想,就是把世界上任何离散的、无序的物体,映射到一个连续的、有意义的向量空间中。
所以,万物皆可 Embedding!
🔹1. 用户 Embedding:你的购物 or 兴趣 DNA
电商平台会根据你的点击、购买、收藏记录,为你生成一个用户 Embedding。这个向量,就是你的购物 DNA 的高度浓缩。
- 同时,每个商品也有一个商品 Embedding。
- 推荐系统是怎么工作的?它在庞大的商品库里,寻找那些商品 Embedding 与你的用户 Embedding 在空间中距离最近的商品,然后推荐给你。这就是 “猜你喜欢” 的底层逻辑。
- 听歌软件、短视频 App,同理。你的听歌品味和刷视频偏好,也都被编码成了一个 Embedding 向量。
🔹2. 图像 Embedding:让 AI 看懂图片
- 一个深度学习模型(如 CNN)可以把一张完整的图片,也编码成一个向量。这个向量就代表了图片的核心内容。
- 以图搜图功能,就是把你上传的图片的 Embedding,去和一个存有海量图片 Embedding 的数据库进行比对,找出最相似的那些。
🔹3. 社交网络 Embedding:人际关系的数学表达
- 在一个社交网络里,每个人可以被看作一个节点。通过分析你和谁是好友、你们共同关注了谁,也可以为每个人生成一个 Embedding。
- 这个 Embedding 可以用来发现社区、推荐好友,甚至预测用户的行为。
🔹4. 多模态 Embedding:打通所有感官
- 还记得我们上一期讲的多模态吗?它的关键是 —— 共享语义空间,就是靠 Embedding 实现的。
- CLIP 模型,就是通过对比学习,把一张 “狗” 的图片的 Embedding,和 “一只可爱的狗” 这段文字的 Embedding,在空间中拉到同一个位置。
- Embedding,就是构建多模态巴别塔的唯一蓝图和砖块。