转载:小红书 AI产品赵哥
前言🔖
你有没有发现,现在的 AI 大模型(比如 ChatGPT、Claude)虽然很聪明,但它们都有一个共同的痛点:它们像是一个被锁死在浏览器窗口里的大聪明。
- 🧐 你问它:“帮我查查我昨天写的那个 Google 文档里关于预算的部分。” 它两手一摊:“对不起,我访问不了你的 Google 文档。”
- 🧐 你让它:“帮我分析一下我在本地电脑上存的那个 CSV 表格。” 它无奈地说:“请你先把文件上传给我。”
- 🧐 你想让它:“直接去我的数据库里查一下上个月的销售数据。” 它只能摇头:“我连不上你的数据库。”
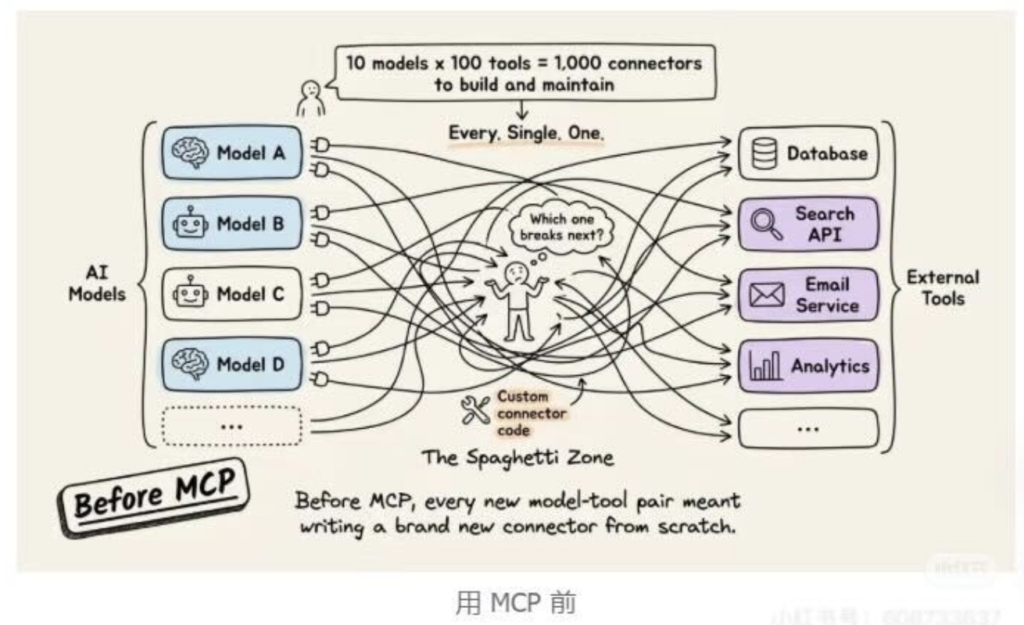
痛点就在于:大模型很强,但你的数据很散。你的数据分散在Google Drive、Slack、Notion、本地硬盘、公司数据库等各个角落。要让大模型用到这些数据,你需要一个个去开发连接器(Integrations)。这就像是给每一种家电都要配一种专门的插座,很麻烦,且割裂。
为了解决这个问题,Anthropic 站出来了:“我们需要一个标准!我们需要一个 AI 界的 USB 接口!”
于是,MCP (Model Context Protocol,模型上下文协议) 诞生了。
一、啥是 MCP?🔖
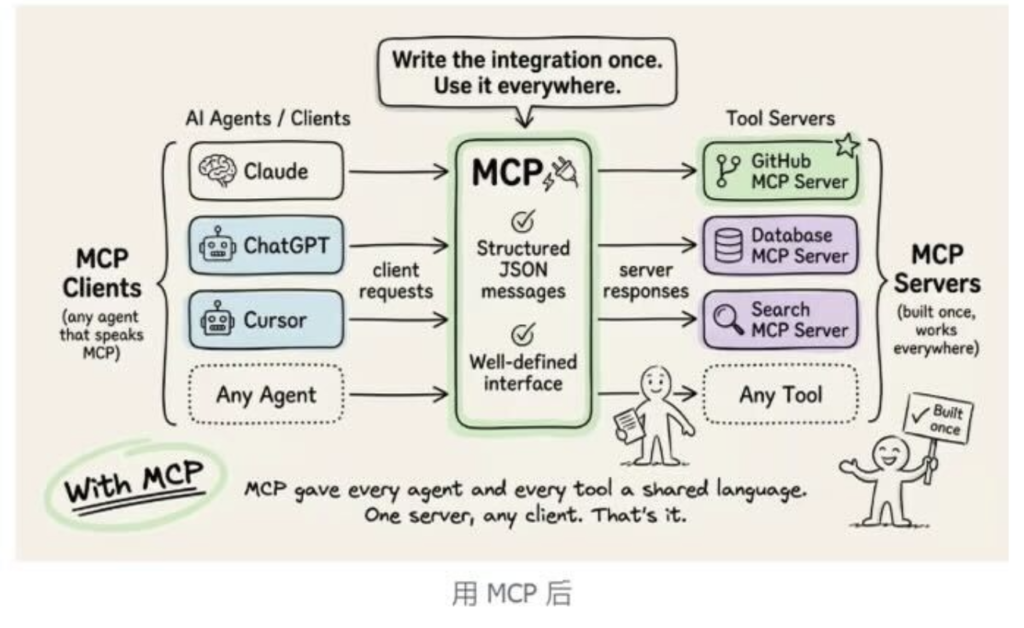
💡 MCP 是一个开放的标准协议,它规定了 AI 模型(如 Claude)应该如何与外部的数据源和工具(如 Google Drive, Slack, 数据库)进行沟通和连接。
🔹1. 没有 MCP 的世界:乱成一锅粥
在 MCP 出现之前,如果你想开发一个能让 Claude 访问你的 Google Drive 的应用,你需要:
- 去读 Google Drive 的 API 文档。
- 写一套专门的代码,把 Google Drive 的数据格式,转换成 Claude 能看懂的 Prompt(提示词)。
- 如果明天你想换成让 ChatGPT 访问 Google Drive?对不起,代码得重写,因为 ChatGPT 的接口不一样。
- 如果你想让 Claude 访问 Slack?对不起,代码得重写,因为 Slack 的 API 不一样。
这是一个很费劲的活儿:n 个大模型,乘以 m 个数据源,你需要写n∗m种不同的连接代码。
🔹2. 有了 MCP 的世界:一插即用
MCP 就像是 USB 接口。
- USB 协议规定了:不管你是鼠标、键盘、打印机还是 U 盘,只要你符合 USB 标准,插到电脑上就能用。
- MCP 协议规定了:不管你是 Google Drive、Slack 还是本地文件系统,只要你把自己封装成一个MCP 服务(MCP Server),** 任何支持 MCP 的 AI 客户端(MCP Client,如 Claude Desktop App)** 都能直接连接你、读取你的数据、使用你的功能。
从此,n × m 的灾难,变成了 n + m 的优雅。数据源只需要开发一次 MCP Server,就能被所有支持 MCP 的 AI 模型使用。
二、MCP 的构成 —— Client、Server、Host
要理解 MCP 是怎么工作的,我们需要拆解它的三个主要角色。这有点像我们在餐厅点菜的过程。
🔹1. MCP Host(宿主):那个 “点菜的 APP”
MCP Host 是发起连接的程序。目前最典型的 Host 就是 Claude Desktop App(Claude 的桌面客户端),或者像 Cursor 这样的 IDE。
- 角色:它是用户直接交互的界面。它负责管理各种连接,把用户的需求转发给大模型,并把大模型生成的指令转发给 MCP Server。
- 大白话:它就像是你手机上的外卖 APP。你在这个 APP 里操作,APP 负责去联系各个商家。
🔹2. MCP Client(客户端):APP 里的调度员
Client 通常是嵌在 Host 内部的一个模块。它负责与 MCP Server 建立通过,维持连接(通常是一对一的连接)。
- 角色:它维持与 Server 的对话通道,把 “我们要查数据” 的请求发过去,把 Server 发回来的 “这是数据” 的响应接回来。
🔹3. MCP Server(服务器):具体的商家
这是最关键的部分。每一个想要被 AI 访问的数据源,都需要把自己封装成一个 MCP Server。
- 角色:它守着自己的那一亩三分地儿(比如本地文件夹、Google Drive)。
- 能力:它通过 MCP 协议,向外暴露三种核心能力(这被称为 MCP 的三大支柱,我们后面细说):
- a. 资源 (Resources):我有什么数据?
- b. 提示 (Prompts):你应该怎么问我?
- c. 工具 (Tools):我能帮你干什么活?
- 大白话:
- 一个 “Google Drive MCP Server” 会告诉 Client:“我有读取文档的能力(资源),你可以让我搜文件(工具)。”
- 一个 “本地文件 MCP Server” 会告诉 Client:“我有访问你 D 盘的能力,你可以让我读取 txt 文件。”
🔹整个流程是这样的:
- 你在 Claude 桌面版(Host)里说:“帮我分析 D 盘那个 report.txt。”
- Claude 桌面版里的 MCP Client,找到了正在运行的 “本地文件 MCP Server”。
- Client 通过 MCP 协议发指令:“好嘞,我要读 report.txt。”
- Server 去 D 盘读到了内容,通过 MCP 协议传回给 Client。
- Client 把内容喂给 Claude 大模型。
- Claude 分析完,把结果展示给你。
全程你不需要写一行代码,也不需要上传文件,一切都在本地或安全的链接中自动完成。
三、MCP Server 的三大能力 —— Resources、Prompts、Tools🔖
MCP 协议之所以强大,是因为它不仅仅是传数据,它还定义了 AI 与世界交互的三种标准模式。这就像是它规定了三种握手姿势。
🔹1. Resources(资源):像读文件一样读世界
这是最基础的模式。它把所有的数据,都抽象成了 “文件”。
- 定义:Server 向 Client 暴露一系列可被读取的数据块。
- 抽象:
- 你的数据库记录,可以被抽象成一个 Resource。
- 你的API 返回的 JSON,可以被抽象成一个 Resource。
- 你的系统日志,可以被抽象成一个 Resource。
- 好处:对于大模型来说,它不需要知道这是个 SQL 数据库还是 API,它只需要知道这里有个东西可以读,就像读一个文本文件一样简单。
- 实时性:Resources 支持订阅机制(Subscribe)。这意味着,如果数据库里的数据变了,Server 可以主动推给 Client,让 AI 实时知道数据更新了。
🔹2. Prompts(提示):把专家经验固化下来
这是为了解决提示词工程(Prompt Engineering)太难的问题。
- 痛点:要让 AI 用好一个复杂的工具(比如代码分析工具),用户通常需要写很长、很专业的提示词。普通用户根本写不出来。
- MCP 的解法:Server 的开发者(最懂这个工具的人),可以把最佳的提示词模板(Prompt Template)直接写在 Server 里,通过 MCP 暴露给用户。
- 具象过程:
- 一个 “代码分析 MCP Server” 可以提供一个叫
analyze-bug的 Prompt。 - 用户在 Claude 里不需要写 “请你作为一个资深程序员,检查这段代码……”,只需要选择
analyze-bug这个指令。 - Claude 就会自动加载 Server 里预设好的那段完美的提示词,用户只需要填入代码片段即可。
- 一个 “代码分析 MCP Server” 可以提供一个叫
- 意义:这让专家经验可以像软件功能一样被分发和复用。
🔹3. Tools(工具):让 AI 有手有脚
- 它让 AI 从只能看变成了可以动。
- 定义:Server 暴露一些可执行的函数,并告诉 AI 这些函数是干嘛的、需要什么参数。
- 流程:
- a. AI(大模型)分析用户的意图,发现需要干活。
- b. AI 查看当前连接的 MCP Server 里有哪些 Tools。
- c. AI 决定调用某个 Tool,并生成需要的参数(比如
search_files(query="budget"))。 - d. Client 把这个调用请求发给 Server。
- e. Server 执行真正的代码(比如去调 Google API,或者去执行一个 Python 脚本)。
- f. Server 把执行结果(比如 “找到了 3 个文件……”)返回给 AI。
- g. AI 根据结果生成最终回答。
- 安全性:MCP 协议在设计时非常注重安全。Tools 的执行通常需要 Human-in-the-loop(用户确认),防止 AI 自作主张删了你的文件。
四、为什么 MCP 是 AI 时代的 HTTP?🔖
你可能会问:“这不就是 API 吗?或者 OpenAI 的 Plugins 吗?有什么了不起?”
但其实,MCP 的野心和格局,远不止于此。
🔹1.去中心化与本地优先 (Local-First)
- OpenAI 的 Plugins,通常要求你把数据传到云端,或者服务必须部署在公网上。
- MCP 天生支持本地运行。你可以把一个 MCP Server 跑在你自己的笔记本上,通过标准输入输出(stdin/stdout)和 Claude 桌面版通信。
- 这意味着:你的隐私数据(如本地代码库、私人日记)永远不出你的电脑,就能被 AI 处理。这对于企业应用和隐私敏感用户来说,是杀手级的优势。
🔹2. 统一的标准,打破生态壁垒
- 在此之前,LangChain 有自己的工具标准,AutoGPT 有自己的,OpenAI 有自己的。开发者疲于奔命。
- Anthropic 推出 MCP,并将其开源,意在建立一个中立的、跨平台的标准。如果这个生态做起来,以后你写一个 MCP Server,就能同时服务于 Claude、ChatGPT、Llama 等所有模型。
🔹3. 上下文的流动
- MCP 的全称是 Model Context Protocol。它强调的是上下文(Context)的注入。
- 通过 MCP,你的 IDE(如 Cursor)可以把当前打开的文件、光标的位置、报错的日志,全部打包成 Context,喂给 AI。AI 不再是一个瞎子,它能精准地感知到你当前的工作现场。
五、实战 —— 如何拥有一个 MCP 系统?🔖
对于普通用户和开发者,现在怎么玩 MCP?
🔹对于普通用户:
- 下载 Claude Desktop App(目前仅支持 macOS 和 Windows)。
- 你需要安装一些 MCP Servers。
- Anthropic 官方提供了一些示例 Servers(如 Google Drive,Postgres,Filesystem)。
- 这通常需要一点点命令行的操作(比如配置一个配置文件
claude_desktop_config.json)。
- 配置好后,重启 Claude App,你就会发现那个回形针图标下,多出了很多能力。你可以直接问它:“查查我电脑里关于旅行的笔记”。
🔹对于开发者:
- Anthropic 提供了 TypeScript SDK 和 Python SDK。
- 你可以很容易地把你的内部工具封装成一个 MCP Server。
- 比如,你们公司有一个内部的员工查询系统。你写几十行 Python 代码,用 MCP SDK 包装一下,它就变成了一个 Server。
- 然后,全公司的同事用 Claude 时,都能直接查员工信息了。
- 你还可以利用 Smithery 这样的平台,它像是一个 “MCP Server 的应用商店”,你可以从中发现和安装各种现成的 Server。