前言🔖
很多刚接触本地大模型的朋友都有同感:Ollama自带的模型库不够用,想用上自己下载的精品量化模型、全精度模型,或是像Qwen3.5-35B这样的定制版模型,却不知道怎么接入Ollama。
Modelfile是关键🔖
Ollama不支持直接拖拽GGUF等模型文件运行,需要通过Modelfile做一层“配置绑定”——相当于给模型写一份说明书,告诉Ollama:模型路径、对话模板、停止符、写作参数、多模态配置。这份文件写对,部署就成功了90%。
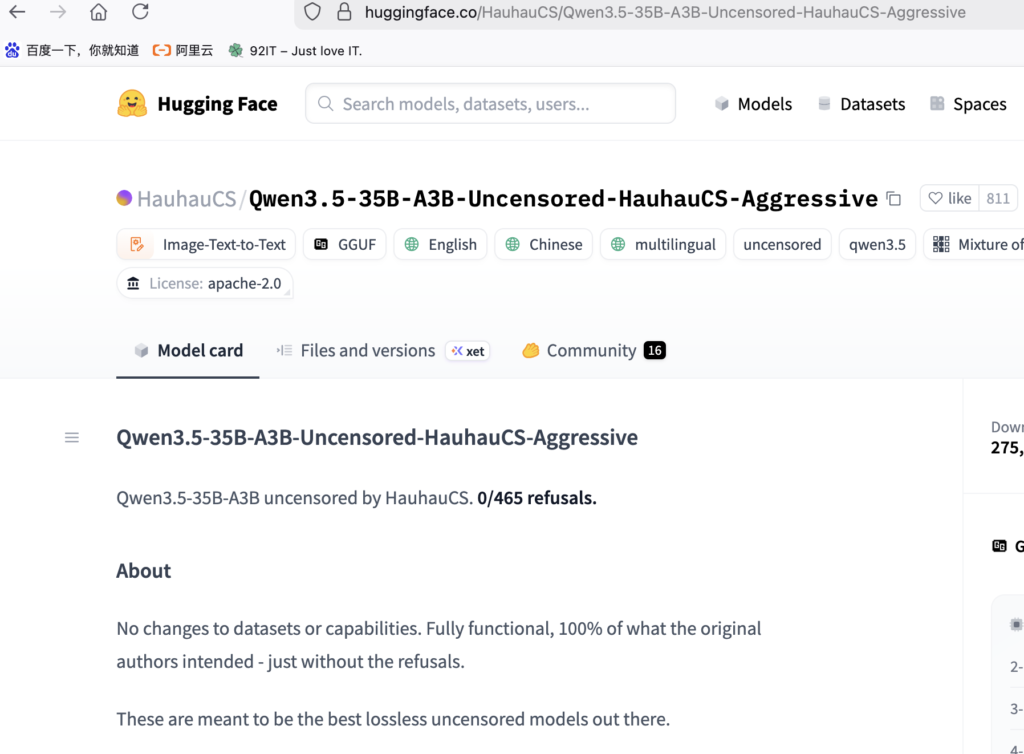
🔹1.下载GGUF模型:去Hugging Face搜索对应模型
https://huggingface.co/HauhauCS/Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive
比如我们可以去Hugging Face下载最新的千问3.5 35B模型,该模型属于微调模型,去除了一些敏感信息的过滤。
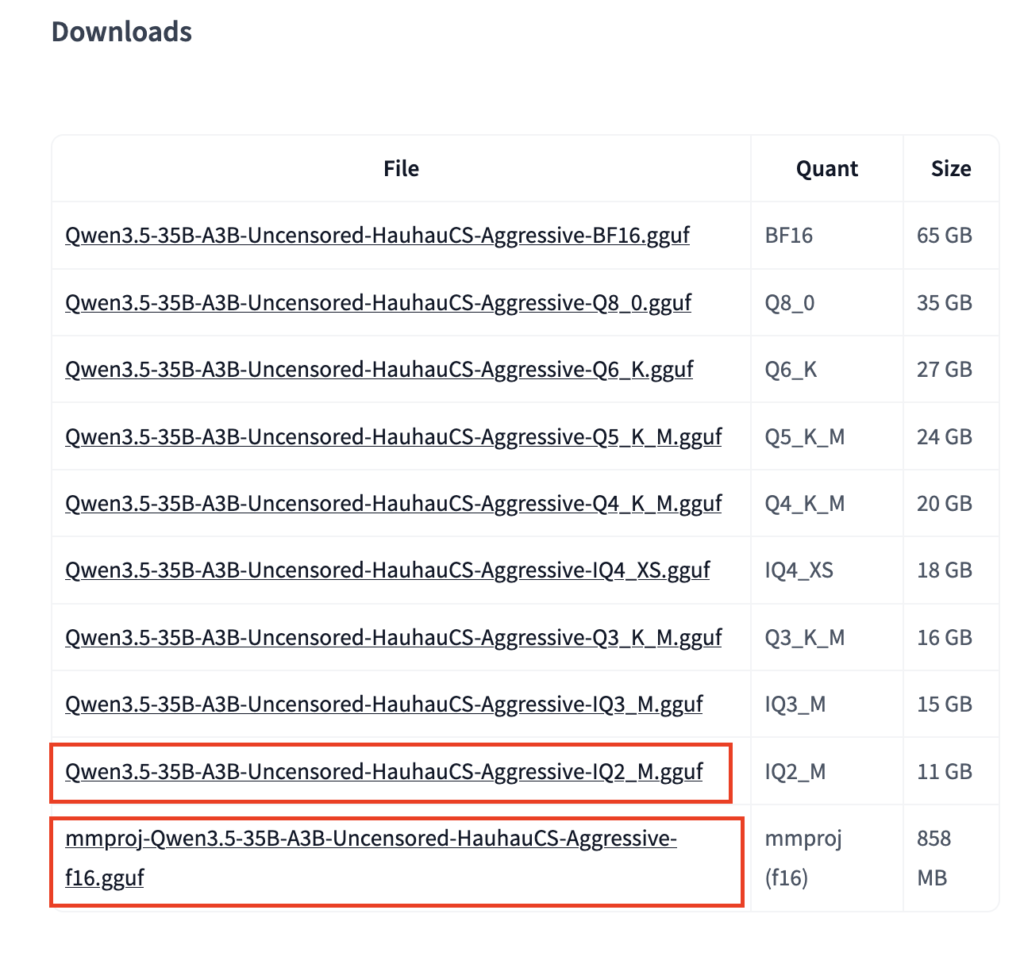
- Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive-IQ2_M.gguf 等是量化模型文件
- mmproj-Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf 是图片识别模型
这里文件模型和图片模型是分开的,组合在一起形成了多模态的大模型。模型根据电脑的配置,下载对应的版本就可以了。
🔹2 准备Modelfile文件:模型下载到本地目录以后,在模型的同级目录下,我们可以创建一个Modelfile文件,命名为Modelfile,无后缀名。
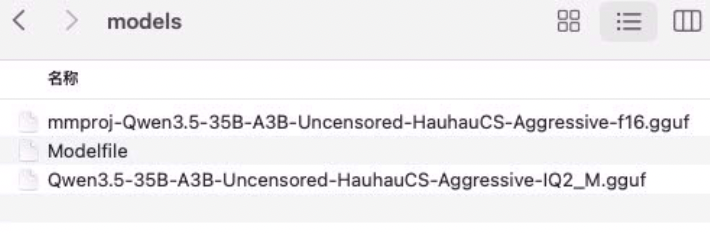
下面是文件的例子
# 核心:指向你的 35B-IQ2_M.gguf 模型文件(替换为实际路径)
FROM ./Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive-IQ2_M.gguf
# 1。多模态核心配置
# 指定多模态投影文件
# PARAMETER mmproj ./mmproj-Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf
# 声明模型类型为多模态
# PARAMETER multimodal true
# 2. 对话模板 (Qwen 系列保持原样)
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ range .Messages }}<|im_start|>{{ .Role }}
{{ .Content }}<|im_end|>
{{ end }}<|im_start|>assistant
"""
# 3. 停止符 (清理重复,保留必要)
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|im_start|>"
# 防止泄露思考过程 (如果你的模型有这个倾向)
PARAMETER stop "Here's a thinking process"
PARAMETER stop "思考过程"
# 4. 回答结果专用参数配置
PARAMETER num_ctx 32768
PARAMETER temperature 1
PARAMETER presence_penalty 0.3
PARAMETER repeat_penalty 1.2
PARAMETER frequency_penalty 0.7
PARAMETER top_p 0.85
PARAMETER top_k 70
PARAMETER min_p 0.05
一些基本参数说明
关键参数说明
FROM
指定基础模型,可以是本地路径(.gguf/.bin)或 Ollama 模型库中的名称(如 llama3:8b)。
支持多模型合并(需模型架构兼容)。
PARAMETER
temperature: 控制生成随机性(0-1,值越高越自由)。
num_ctx: 上下文长度(影响内存占用)。
stop: 停止生成的标记词(例如 "</s>")。
num_gpu_layers: 启用 GPU 加速的层数(加快推理速度)。
SYSTEM
定义模型的默认行为,例如角色设定或回答限制。
TEMPLATE
定义对话格式模板,需与模型训练时的格式对齐(对生成质量至关重要)。
这个文件 mmproj-Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf 不是一个完整的模型,而是一个 多模态投影器(Multi-Modal Projector) 文件。
它不能单独运行,必须配合主模型(即你之前提到的 Qwen3.5-35B...gguf)一起使用,才能让模型具备识图/视觉能力。
⚠️ 重要说明:Ollama 的限制
目前 Ollama 的 Modelfile 并不直接支持加载外部的 mmproj 文件。 Ollama 通常要求多模态模型是“打包好”的(即投影器权重已经合并到主模型中,或者使用 Ollama 官方库中已支持的多模态模型如 llava)。
如果你想使用这个独立的 mmproj 文件 + 主模型组合,推荐使用 llama.cpp 原生工具,而不是 Ollama。
安装创建模型🔖
可以用mac的终端,先切换到模型所在文件夹,用下面的命令查看本地的Ollama目前有哪些模型
Ollama list
Ollama list NAME ID SIZE MODIFIED qwen35b-iq2m:latest 3bb41542e0ef 11 GB 30 minutes ago bge-m3:latest 790764642607 1.2 GB 6 days ago qwen3.5:9b 6488c96fa5fa 6.6 GB 11 days ago
删除一个模型
Ollama rm qwen35b-iq2m:latest
用指定的Modelfile文件创建模型
等待显示“success”,模型就部署完成了,全程无需联网,只读取本地文件。
ollama create qwen35b-iq2m -f Modelfile
ollama create qwen35b-iq2m -f Modelfile gathering model components copying file sha256:eb9dc9196536bde5de8a7dbddb53a422bc80505d7c7d36ebb9b84648e6b6a793 100% parsing GGUF using existing layer sha256:eb9dc9196536bde5de8a7dbddb53a422bc80505d7c7d36ebb9b84648e6b6a793 creating new layer sha256:6d2bd142f1177e6ba3b61d61c441ba8df5d62a476478883d5f9a92712205e784 creating new layer sha256:31f8a8ec7e0859ce67f800b3731801278fa5cb172f064d50621a0c6267ee75a0 writing manifest success
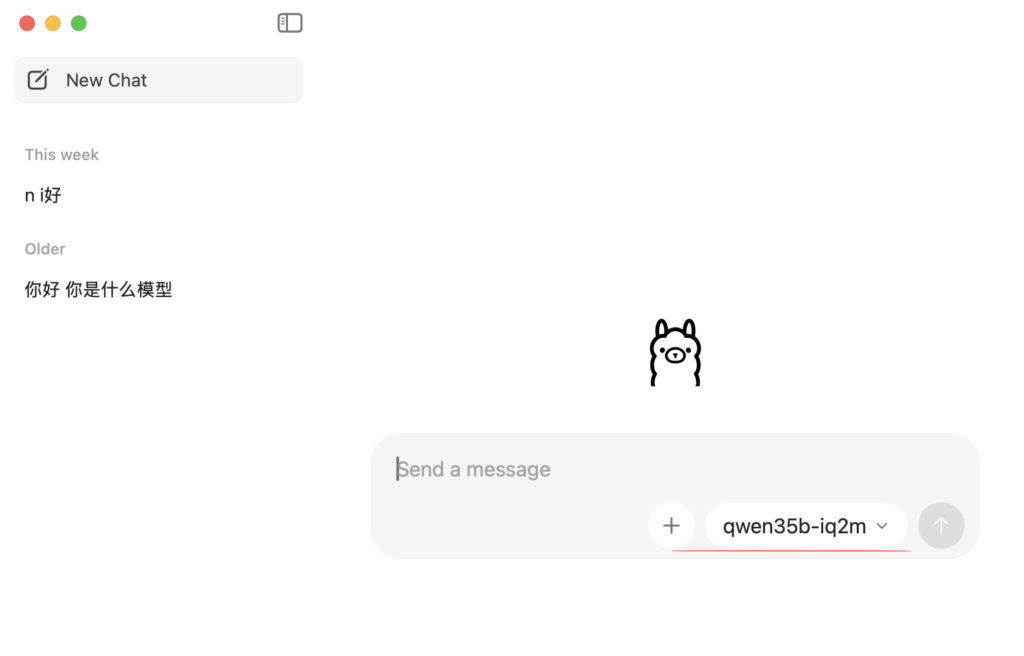
创建成功以后,就会在Ollama的Chat UI画面看到该模型,并愉快的使用了。