转载:Logback、Log4j、SLF4J 、ELK、EFK、Loki 傻傻分不清楚?
前言 🔖
今天我想和大家聊聊一个看似基础,却让无数开发者困惑的问题:日志框架这么多,它们到底是什么关系? Logback、Log4j2、SLF4J、ELK、EFK、Loki……这些名词像是一锅粥,很多人用了多年仍分不清彼此。
有些小伙伴在工作中可能遇到过这样的情况:系统报错,你需要查日志,却不知道该去Kibana里搜,还是登录服务器用tail -f命令看本地文件;或者明明引入了日志依赖,运行时却遇到ClassNotFoundException,控制台一片“SLF4J: No binding found”的警告。
这通常意味着你对应用级日志记录和系统级日志管理这两大体系的理解出现了混淆。
今天这篇文章专门跟大家一起聊聊这个话题,希望对你会有所帮助。
去年我遇到一个典型案例:一家电商公司的核心交易系统在“双11”大促期间出现间歇性超时。
开发团队的第一反应是查日志。
但问题来了:他们的系统混合使用了三种日志方式:
- 1. 部分老服务直接使用
System.out.println - 2. 一些服务使用Log4j 1.x
- 3. 新服务使用Logback
更糟糕的是,这些日志分散在几十台服务器上,没有统一的收集和检索系统。为了定位问题,运维不得不登录每台服务器,用grep命令筛选日志。等他们拼凑出完整的调用链时,高峰流量已经过去了,直接经济损失超过百万。
这个案例揭示了日志管理的三个核心问题:
- 1. 应用内如何规范、高效地记录日志?
- 2. 如何统一不同技术栈的日志API?
- 3. 如何集中管理和分析分布式的日志?
这正是我们今天要解答的。
02 应用级日志框架:SLF4J的门面模式智慧🔖
首先,我们来解决应用内部的问题。在Java生态中,日志框架的发展经历了从混乱到统一的过程。
SLF4J(Simple Logging Facade for Java)是这个统一过程的关键产物。它不是具体的日志实现,而是一个门面(Facade) ,定义了一套统一的日志API。
// 这是使用SLF4J API的典型方式
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class OrderService {
// 关键点1:通过SLF4J的工厂获取Logger
private static final Logger logger = LoggerFactory.getLogger(OrderService.class);
public void createOrder(OrderRequest request) {
// 关键点2:使用参数化日志,避免字符串拼接的性能开销
logger.info("开始创建订单,用户ID: {}, 商品ID: {}",
request.getUserId(), request.getProductId());
try {
// 业务逻辑处理
Order order = processOrder(request);
// 关键点3:使用占位符,而不是字符串连接
logger.debug("订单处理详情: {}", order);
} catch (BusinessException e) {
// 关键点4:错误日志记录异常堆栈
logger.error("创建订单失败,请求参数: {}", request, e);
throw e;
}
}
}
SLF4J的门面模式设计精妙之处:
- 1. 解耦:业务代码只依赖SLF4J的API,不关心底层是Logback还是Log4j2
- 2. 性能优化:参数化日志logger.debug(“Value: {}”, arg)在日志级别关闭时,避免了字符串拼接的开销
- 3. 兼容性:通过桥接器(Bridge)可以兼容老项目的Log4j、JUL等API
这种设计的背后是面向接口编程的思想。就像JDBC定义了数据库操作的接口,各家数据库提供具体实现一样,SLF4J定义了日志操作的接口,让Logback、Log4j2等去实现。
03 Logback vs Log4j2:实现者的较量🔖
有了统一的门面,我们再来看看两大主流实现:Logback和Log4j2。
🔹Logback:Spring Boot的默认选择
Logback由Log4j创始人开发,是SLF4J的原生实现。它被Spring Boot选为默认日志框架,不是偶然的。
Logback的优势:
- 1. 零依赖:与SLF4J天然集成,无需额外的适配层
- 2. 配置灵活:支持XML和Groovy配置,有强大的条件化配置
- 3. 自动重载:配置文件修改后可以自动重新加载
<!-- logback-spring.xml 配置文件示例 -->
<configuration scan="true" scanPeriod="30 seconds">
<!-- 根据不同环境使用不同配置 -->
<springProfile name="dev">
<root level="DEBUG">
<appender-ref ref="CONSOLE" />
</root>
</springProfile>
<springProfile name="prod">
<root level="INFO">
<appender-ref ref="ROLLING_FILE" />
<appender-ref ref="ERROR_FILE" />
</root>
</springProfile>
<!-- 控制台输出 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- 彩色日志输出,便于开发调试 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss} %highlight(%-5level) [%thread] %cyan(%logger{36}) - %msg%n</pattern>
</encoder>
</appender>
<!-- 滚动文件输出 -->
<appender name="ROLLING_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/app/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 按天归档,压缩旧日志 -->
<fileNamePattern>/var/log/app/app.%d{yyyy-MM-dd}.%i.log.gz</fileNamePattern>
<maxHistory>30</maxHistory>
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
</configuration>
🔹Log4j2:性能的极致追求者
Log4j2是Apache对经典Log4j的完全重写,它解决了Log4j 1.x和Logback的一些架构缺陷。
Log4j2的核心优势:
- 异步日志性能:基于LMAX Disruptor环形队列,异步日志性能比Logback高10倍以上
- 无垃圾回收压力:在垃圾收集敏感的系统中表现优异
- 插件化架构:扩展性更好
<!-- log4j2.xml 配置文件示例 -->
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN" monitorInterval="30">
<Appenders>
<!-- 异步文件Appender -->
<RandomAccessFile name="ASYNC_FILE" fileName="logs/app.log" immediateFlush="false">
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</RandomAccessFile>
<!-- 异步日志器,核心性能优势 -->
<Async name="ASYNC" bufferSize="1024">
<AppenderRef ref="ASYNC_FILE"/>
</Async>
</Appenders>
<Loggers>
<!-- 自定义Logger配置 -->
<Logger name="com.example.service" level="DEBUG" additivity="false">
<AppenderRef ref="ASYNC"/>
</Logger>
<Root level="INFO">
<AppenderRef ref="ASYNC"/>
</Root>
</Loggers>
</Configuration>
🔹性能对比测试数据
我曾在压测环境中对比两者的性能(单线程,100万条日志):
| 测试场景 | Logback同步 | Logback异步 | Log4j2同步 | Log4j2异步 |
|---|---|---|---|---|
| INFO级别输出到文件 | 4.2秒 | 2.1秒 | 3.8秒 | 0.8秒 |
| DEBUG级别(不输出) | 1.8秒 | 0.9秒 | 0.5秒 | 0.1秒 |
| 内存占用 | 中等 | 中等 | 较低 | 最低 |
从数据可以看出,Log4j2的异步日志在性能上有压倒性优势,特别是在高并发、高频日志的场景下。
04 桥接器的魔法:统一历史遗留系统🔖
有些小伙伴在工作中可能接手过老项目,里面混杂着各种日志API。这时,SLF4J的桥接器就派上用场了。
<!-- 在pom.xml中配置桥接器,统一日志门面 -->
<dependencies>
<!-- 1. SLF4J API -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.7</version>
</dependency>
<!-- 2. 选择一种实现:Logback -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.4.7</version>
</dependency>
<!-- 3. 桥接Log4j 1.x -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>2.0.7</version>
</dependency>
<!-- 4. 桥接JUL (java.util.logging) -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jul-to-slf4j</artifactId>
<version>2.0.7</version>
</dependency>
<!-- 5. 桥接Apache Commons Logging -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>2.0.7</version>
</dependency>
</dependencies>
桥接器的工作原理很有趣:它劫持了其他日志API的调用,转发给SLF4J。比如log4j-over-slf4j提供了一个与Log4j 1.x API完全相同的包结构,但内部实现是调用SLF4J。
05 系统级日志方案:从ELK到Loki的演进🔖
解决了应用内的问题,我们来看看系统层面。当服务从单体架构演进到微服务,日志分散在上百个实例中,集中式日志系统就成为刚需。
🔹ELK Stack:经典的三剑客
ELK是Elasticsearch、Logstash、Kibana三个开源产品的首字母缩写,它们各自分工明确:
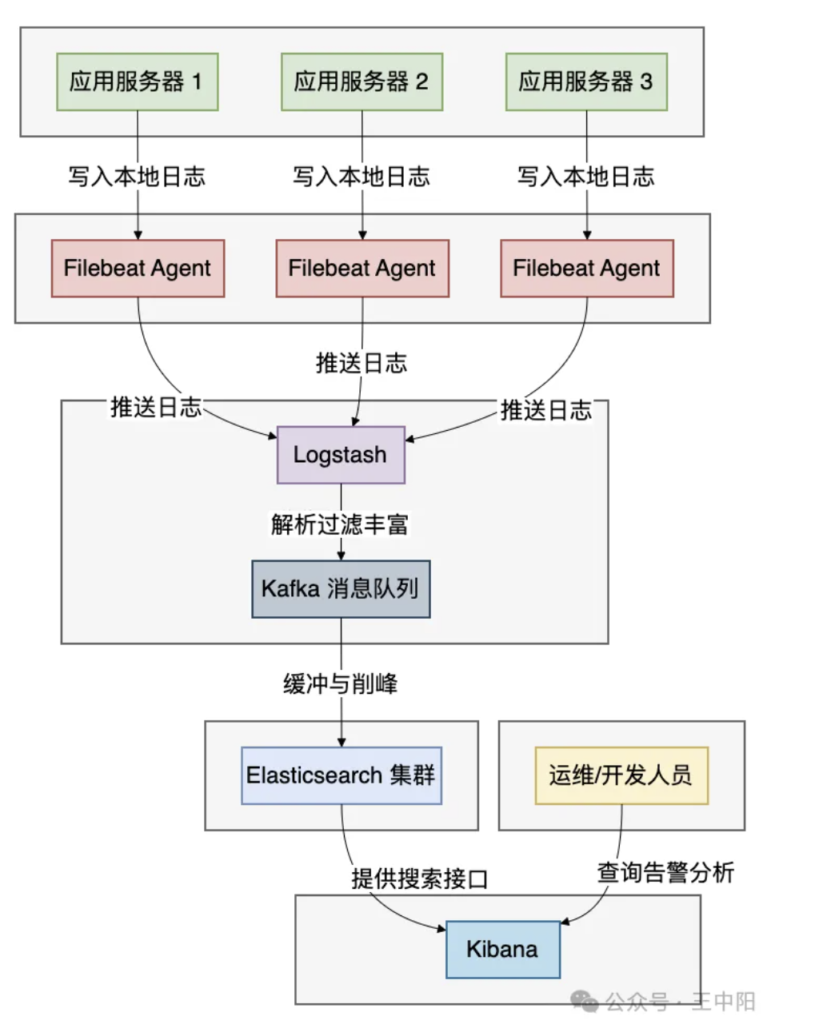
各组件的职责:
- 1. Logstash:数据收集引擎,支持各种输入源,有强大的过滤插件
- 2. Elasticsearch:分布式搜索分析引擎,负责存储和检索日志
- 3. Kibana:数据可视化平台,提供日志搜索、分析图表等功能
ELK的典型配置:
# Logstash配置文件 logstash.conf
input {
# 从Filebeat接收日志
beats {
port => 5044
}
}
filter {
# 解析JSON格式的日志
if [message] =~ /^{.*}$/ {
json {
source => "message"
target => "log_content"
}
}
# 提取时间戳
date {
match => [ "timestamp", "ISO8601" ]
target => "@timestamp"
}
# 添加业务标签
if [log_content][service] == "order" {
mutate {
add_tag => [ "order_service" ]
}
}
}
output {
# 输出到Elasticsearch
elasticsearch {
hosts => [ "es-node1:9200", "es-node2:9200" ]
index => "app-logs-%{+YYYY.MM.dd}"
}
# 同时输出到监控系统
if "_grokparsefailure" in [tags] {
exec {
command => "echo 'Parse failed: %{message}' >> /tmp/failed.log"
}
}
}
🔹EFK Stack:云原生时代的进化
随着Docker和Kubernetes的流行,ELK的变种EFK Stack(Elasticsearch + Fluentd + Kibana)成为云原生环境的主流选择。
为什么用Fluentd替代Logstash?
- 1. 资源效率:Fluentd用C和Ruby编写,内存占用约40MB,而Logstash(JVM)需要约500MB
- 2. 部署友好:Fluentd有丰富的Kubernetes插件,更适合容器环境
- 3. 可靠性:内置的缓冲和重试机制更健壮
# Fluentd在K8s中的配置示例
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluent.conf: |
<source>
@type tail
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
tag kubernetes.*
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match kubernetes.**>
@type elasticsearch
host elasticsearch
port 9200
logstash_format true
logstash_prefix fluentd
buffer_chunk_limit 2M
buffer_queue_limit 32
flush_interval 5s
max_retry_wait 30
disable_retry_limit
num_threads 8
</match>
🔹Loki:日志管理的新哲学
Loki由Grafana Labs开发,采用了与ELK完全不同的设计哲学:只索引元数据,不索引日志内容。
Loki的架构创新:
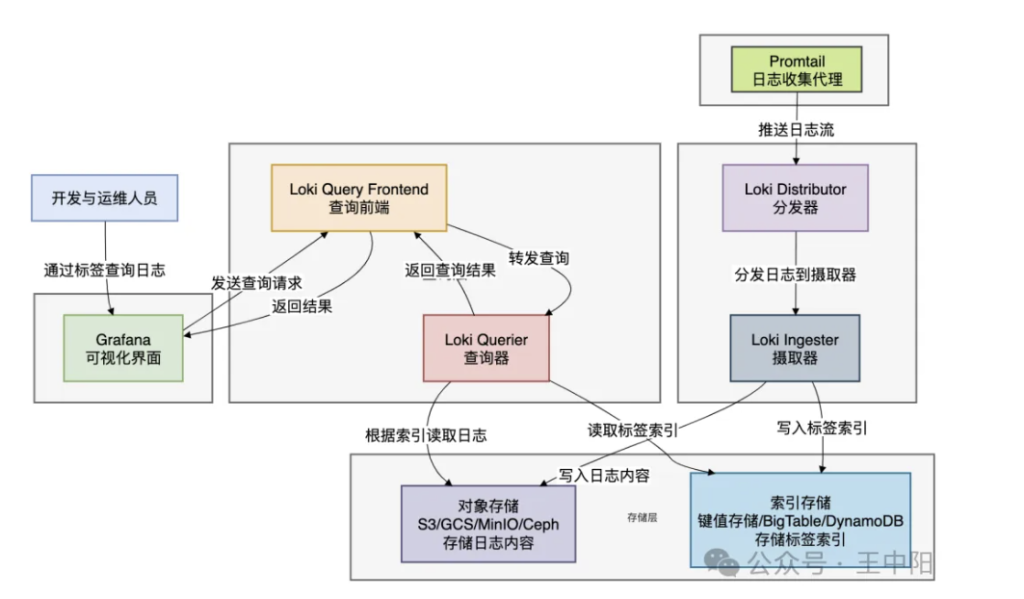
Loki的核心特点:
- 成本效益:存储成本约为ELK的1/10,因为不索引日志内容
- 云原生友好:使用对象存储(S3、GCS),天生适合云环境
- Grafana集成:与Prometheus监控数据在同一界面展示
06 全方位对比:如何根据场景选择
06 全方位对比:如何根据场景选择🔖
现在我们对所有技术都有了深入了解,下面是一个全面的对比表格:
应用级日志框架对比
| 特性维度 | SLF4J | Logback | Log4j2 |
|---|---|---|---|
| 定位 | 日志门面/抽象层 | 具体实现 | 具体实现 |
| 性能 | N/A(接口层) | 良好 | 卓越(特别是异步) |
| 内存管理 | N/A | 一般 | 优秀(GC友好) |
| 配置方式 | N/A | XML/Groovy | XML/JSON/YAML |
| 自动重载 | N/A | 支持 | 支持 |
| Spring Boot默认 | 是(通过接口) | 是(2.x之前) | 是(2.x之后可选) |
| 最佳适用场景 | 所有Java项目 | Spring Boot传统项目 | 高性能、高并发系统 |
系统级日志方案对比
| 特性维度 | ELK Stack | EFK Stack | Loki |
|---|---|---|---|
| 核心组件 | Logstash+ES+Kibana | Fluentd/Fluent Bit+ES+Kibana | Loki+Grafana |
| 设计哲学 | 全文索引,强大搜索 | 全文索引,云原生优化 | 标签索引,成本优先 |
| 存储成本 | 高(索引所有内容) | 高 | 低(仅索引标签) |
| 查询能力 | 强大(全文搜索+聚合) | 强大 | 良好(基于标签筛选) |
| 部署复杂度 | 高 | 中 | 低 |
| 学习曲线 | 陡峭 | 中等 | 平缓 |
| 云原生适配 | 中等 | 优秀 | 优秀 |
| 实时性 | 近实时(秒级) | 近实时(秒级) | 近实时(秒级) |
| 最佳适用场景 | 大型企业,复杂分析需求 | 容器化环境,云原生架构 | 云原生,成本敏感,已有Grafana |
07 实战选型指南🔖
基于我多年的工作经验,总结出以下选型建议:
场景一:初创公司,快速启动
- • 应用日志:Spring Boot默认的Logback + SLF4J
- • 集中日志:SaaS服务(如Logz.io、Datadog),避免自运维成本
- • 理由:快速上线,专注业务
场景二:中型企业,微服务转型
- • 应用日志:逐步迁移到Log4j2,特别是核心交易系统
- • 集中日志:EFK Stack(Kubernetes环境)或ELK(传统虚拟机)
- • 理由:平衡功能与成本,为增长预留空间
场景三:大型互联网公司,海量日志
- • 应用日志:Log4j2异步日志,关键服务添加TraceID
- • 集中日志:分层架构:
- • 实时分析:ELK/EFK,保留7天热数据
- • 长期归档:Loki + 对象存储,存储全量日志
- • 理由:兼顾查询性能与存储成本
场景四:金融/电信,强合规要求
- • 应用日志:Log4j2,配置审计级别的日志策略
- • 集中日志:双ELK集群(生产+审计),日志不可篡改
- • 理由:满足合规,审计追踪
总结🔖
日志技术栈看似复杂,但理解其分层设计思想后,一切都会变得清晰:
- 1. 应用层:SLF4J是必须的门面,Logback适合大多数场景,Log4j2在性能敏感场景是首选
- 2. 系统层:ELK功能全面但成本高,EFK更适合云原生,Loki是成本敏感型选择
- 3. 核心原则:统一门面、异步写入、结构化输出、集中管理
技术选型没有银弹,只有最适合。
我们需要在功能、性能、成本、复杂度之间找到平衡点。
记住,好的日志系统不是技术最先进的,而是最能帮助团队快速定位问题的。
最后送给大家一句话:“日志是系统的日记,记录着它的每一次呼吸和心跳。读懂它,你就能与系统对话。”