背景 🔖
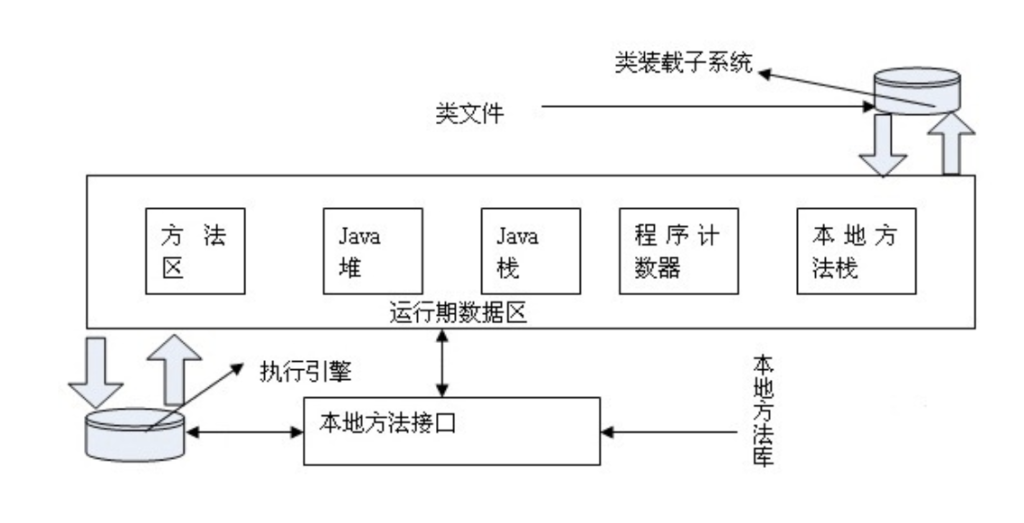
Java程序在运行时,需要在内存中分配空间。为了提高运行效率,就对数据进行了不同的空间划分。因为每一片区域都有特定的数据处理方式和内存管理方式。
1. 方法区(Method Area)🔖
⭐ 存储 类的元数据(类结构、方法字节码、常量池、静态变量等),是所有线程共享的内存区域。
相当于程序的 “字典库”,记录了所有加载的类 “长什么样”(类名、继承关系、方法逻辑等)。
- 细节
- 类加载子系统(图中顶部)会把
.class文件的内容解析后,存入方法区。 - 方法区(Method Area)是 Java 虚拟机(JVM)运行时数据区的一部分,属于所有线程共享的内存区域。在 Java 8 之前,方法区是堆的一个逻辑部分,有个比较著名的别名叫做 “永久代(PermGen)” ;Java 8 及以后,方法区的实现被替换为元空间(Metaspace),使用本地内存而不是 Java 堆内存,避免了方法区内存溢出的一些历史问题。
- 类加载子系统(图中顶部)会把
🔹 方法区存储的内容
- 类的元数据:包括类的基本信息,如类名、访问修饰符、父类、实现的接口列表;类的字段信息,包括字段名、类型、访问修饰符;类的方法信息,如方法名、返回类型、参数列表、方法的字节码、异常表等。例如,对于
public class Person { private String name; public void setName(String name) { this.name = name; } },这些关于Person类的结构定义都会存储在方法区。 - 常量池:分为运行时常量池和字符串常量池。
- 运行时常量池:是类文件中常量池在运行时的表示形式,存储编译期生成的各种字面量(如文本字符串、被声明为 final 的常量值等)和符号引用(如类和接口的全限定名、字段的名称和描述符、方法的名称和描述符 )。比如
String str = "hello";中的"hello"字符串字面量,以及方法调用时对其他类方法的符号引用,都会在运行时常量池中体现。 - 字符串常量池:专门用于存储字符串对象,当使用字符串字面量创建字符串时(如
String s = "world";),JVM 会先检查字符串常量池中是否已经存在该字符串,如果存在则直接返回引用,不存在则在字符串常量池中创建该字符串对象。
- 运行时常量池:是类文件中常量池在运行时的表示形式,存储编译期生成的各种字面量(如文本字符串、被声明为 final 的常量值等)和符号引用(如类和接口的全限定名、字段的名称和描述符、方法的名称和描述符 )。比如
- 静态变量:被
static修饰的变量,其生命周期与类相同,存储在方法区中。比如public class Utils { public static int count = 0; }中的count变量,就存放在方法区,所有对Utils.count的访问和修改,操作的都是方法区中的这个变量。 - 即时编译(JIT)后的代码 :在 Java 程序运行过程中,JVM 的即时编译器会将热点代码(频繁执行的方法等)编译为本地机器码以提高执行效率,编译后的本地机器码也会存放在方法区。
🔹 方法区的作用
- 支持类的加载与运行:类加载子系统将
.class文件加载到 JVM 时,会把解析出来的类的元数据信息存储到方法区。后续 JVM 执行 Java 程序,执行引擎在执行方法时,需要从方法区获取类的结构信息、方法字节码等内容,来确定方法的参数列表、访问权限等,进而正确执行方法。 - 实现常量的共享与管理:常量池使得相同的字面量和符号引用可以被多个类或方法共享,避免重复存储,提高内存利用率。比如多个类中都使用到字符串
"java",在常量池中只会存储一份,各个地方都引用这一份,节省了内存空间。 - 提供静态变量的存储与访问:为静态变量提供了统一的存储位置,方便不同线程对静态变量进行访问和修改,保证了静态变量在类的生命周期内的唯一性和可访问性。
🔹 Java 8 前后方法区实现的差异
- Java 7 及之前:使用永久代实现方法区,永久代在 Java 堆中划分出一块区域来存储方法区数据。但这种方式存在一些问题,比如永久代的大小在启动时需要预先设置,很难根据实际情况进行动态调整,如果设置过小,容易导致永久代内存溢出(
java.lang.OutOfMemoryError: PermGen space);如果设置过大,又会浪费内存。 - Java 8 及之后:引入元空间来替代永久代实现方法区,元空间使用本地内存(Native Memory),而不是 Java 堆内存。元空间的大小不再像永久代那样受到 Java 堆大小的限制,而是由系统的可用内存决定。同时,元空间在内存管理上更加灵活高效,能根据运行时的需要动态分配和释放内存,降低了内存溢出的风险。
🔹 方法区与其他运行时数据区的交互
- 与 Java 堆:Java 堆用于存储对象实例,而对象所属类的元数据信息在方法区。当通过
new关键字创建对象时,JVM 需要先在方法区获取类的元数据,确认类的结构、构造函数等信息,然后在 Java 堆中分配内存来创建对象实例。 - 与 Java 栈:Java 栈用于存储线程执行方法时的栈帧。当线程调用一个方法时,JVM 会在 Java 栈中创建对应的栈帧,同时需要从方法区获取该方法的字节码指令等信息,来驱动方法的执行。方法执行过程中,如果涉及到对类的静态变量、常量的访问,也是从方法区获取相应的数据。
总之,方法区在 Java 程序的运行过程中扮演着至关重要的角色,它为类的加载、运行提供了必要的元数据和数据存储支持,是 Java 虚拟机能够正确执行 Java 程序的关键组件之一。
2.Java 堆(Java Heap)🔖
⭐ 存储 对象实例(new 出来的对象)和数组,是 JVM 中最大的内存区域,所有线程共享。几乎所有的对象实例以及数组都在堆上分配内存。
- 类比:相当于程序的 “仓库”,所有对象的 “实体” 都存在这里,比如
new User()创建的用户对象、new ArrayList()创建的集合对象。 - 细节:
- 垃圾回收(GC)的主要战场:JVM 的垃圾回收器(如 G1、CMS)会定期扫描堆,回收不再使用的对象,释放内存。
- 堆内存可分为 “新生代”(Eden、Survivor)和 “老年代”,用于优化对象的生命周期管理。
🔹 作用与功能
- 对象内存分配:Java 程序在运行过程中,通过
new关键字创建的对象,都会在 Java 堆中分配内存空间。比如Person person = new Person();,这里创建的Person对象的实例数据,像对象的属性值(如果Person类有name、age等属性),都会存储在 Java 堆中。 - 数组内存分配:除了对象,数组也是在 Java 堆中分配内存。无论是基本数据类型的数组(如
int[] arr = new int[10];),还是引用数据类型的数组(如String[] strArray = new String[5];),其内存空间都来自 Java 堆。数组中的元素数据或者元素的引用,都存储在堆上。 - 垃圾回收主要区域:Java 堆是垃圾回收(Garbage Collection,简称 GC)的主要工作区域。随着程序的运行,会不断创建对象,当这些对象不再被引用(即成为垃圾对象)时,垃圾回收器会定期扫描 Java 堆,回收这些不再使用的对象所占用的内存空间,以便重新分配给新的对象,从而实现内存的高效利用。
🔹 内存结构
Java 堆在逻辑上可以细分为不同的区域,常见的分代结构包括新生代(Young Generation)、老年代(Old Generation),部分垃圾回收器还会划分出永久代(Java 8 之前)或元空间(Java 8 及之后,元空间本质不属于堆,但和类相关的部分信息存储逻辑类似)。
- 新生代:用于存放新创建的对象,又可进一步细分为一个 Eden 区和两个 Survivor 区(通常称为 From Survivor 和 To Survivor) 。大多数新创建的对象会首先分配在 Eden 区,当 Eden 区满时,会触发一次 Minor GC(新生代垃圾回收),存活下来的对象会被移动到 Survivor 区。在多次 Minor GC 后,依然存活的对象会被晋升到老年代。
- 老年代:用于存放经过多次垃圾回收后依然存活的对象,以及一些大对象(超过一定大小,会直接在老年代分配内存)。老年代的垃圾回收频率相对较低,触发的 Full GC(全堆垃圾回收)会回收整个 Java 堆的垃圾对象。
🔹 与其他运行时数据区的关系
- 与方法区:方法区存储类的元数据信息,如类的结构、方法字节码、常量池等。当通过
new关键字创建对象时,JVM 需要先从方法区获取类的元数据,确认类的结构、构造函数等信息,然后在 Java 堆中分配内存来创建对象实例。例如,创建new ArrayList<>()时,要先在方法区找到ArrayList类的相关元数据,再在堆中创建具体的ArrayList对象。 - 与 Java 栈:Java 栈是线程私有的,存储线程执行方法时的栈帧,包括局部变量、操作数栈等。当方法中创建对象时(如
public void test() { Person p = new Person(); }),对象的引用(如p)存储在 Java 栈的局部变量表中,而对象的实际数据则存储在 Java 堆中。
🔹 内存溢出问题
如果 Java 堆的内存空间不足以分配新的对象,并且垃圾回收器也无法回收足够的内存,就会抛出java.lang.OutOfMemoryError: Java heap space异常。导致这种情况的原因可能是对象创建过于频繁、对象生命周期过长没有及时回收、内存泄漏(对象不再使用,但引用没有释放,导致垃圾回收器无法回收)等。
总之,Java 堆是 Java 程序运行时存储对象和数组的核心区域,其内存管理和垃圾回收机制对于程序的性能和稳定性起着至关重要的作用。
🔹 一个容易理解的例子
可以把堆理解为一家餐厅,里面有200张桌子,也就是最多能同时容纳200桌客人就餐,来一批客人就为他们安排一些桌子,如果某天来的客人特别多,超过200桌了,那就不能再接待超出的客人了。当然,进来吃饭的客人不可能是同时的,有的早,有的晚,先吃好的客人,老板会安排给他们结账走人,然后空出来的桌子又能接待新的客人。这里,堆就是餐厅,最大容量200桌就是堆内存的大小,老板就相当于GC(垃圾回收),给客人安排桌子就相当于java创建对象的时候分配堆内存,结账就相当于GC回收对象占用的空间。
Java 栈(Java Stack)🔖
⭐ 线程私有,存储线程执行时的 方法调用栈帧(每个方法调用对应一个栈帧)。
- 类比:相当于线程的 “工作记录本”,记录线程当前 “正在执行什么方法”“方法的局部变量是什么”。
- 细节:
- 栈帧包含:方法的局部变量、方法调用的返回地址、操作数栈(执行字节码指令时的临时数据)。
- 方法调用时,栈帧入栈;方法执行完毕,栈帧出栈(遵循 “先进后出” 原则)。
- 示例:调用
main()→doService()→doDB(),Java 栈会依次压入doDB栈帧 →doService栈帧 →main栈帧,执行完doDB后依次弹出。
Java 栈(Java Stack)是线程私有的内存区域,用于记录线程执行方法时的调用轨迹和临时数据,遵循 “先进后出”(FILO)原则。我们通过一个具体例子和图示来详细说明:
🔹 例子:方法调用链的栈帧变化
假设我们有一个简单的 Java 程序,包含 3 个方法调用:main() → methodA() → methodB(),代码如下:
public class StackDemo {
public static void main(String[] args) { // 方法1
int a = 1;
methodA(a);
}
public static void methodA(int x) { // 方法2
int b = 2;
methodB(x + b);
}
public static void methodB(int y) { // 方法3
int c = 3;
System.out.println(y + c); // 输出:6(1+2+3)
}
}
程序运行时,Java 栈会随着方法调用 “压栈”,随着方法执行完毕 “出栈”,具体过程如下:
🔹 图示:Java 栈的动态变化过程
◾1. 初始状态:主线程启动,栈为空
Java栈(线程私有) ┌─────────────────┐ │ │ ← 栈顶(暂无栈帧) │ │ └─────────────────┘
◾2. 执行main()方法:栈帧入栈
- 当
main()方法被调用时,JVM 在 Java 栈中创建一个 **main栈帧 **,包含:- 局部变量:
args(参数)、a=1; - 操作数栈:执行字节码时的临时数据;
- 返回地址:方法执行完后回到哪里(这里是 JVM 启动入口)。
- 局部变量:
Java栈 ┌─────────────────┐ │ main栈帧 │ ← 栈顶(当前执行方法) │ - 局部变量:args, a=1 │ - 返回地址:JVM入口 ├─────────────────┤ │ │ └─────────────────┘
◾3. main()调用methodA():methodA栈帧入栈
main()中执行methodA(a)时,JVM 暂停main执行,创建 **methodA栈帧 ** 压入栈顶:- 局部变量:
x=1(接收main传来的a)、b=2; - 返回地址:
main方法中调用methodA的下一行代码位置。
- 局部变量:
Java栈 ┌─────────────────┐ │ methodA栈帧 │ ← 栈顶(当前执行方法) │ - 局部变量:x=1, b=2 │ - 返回地址:main的调用处 ├─────────────────┤ │ main栈帧 │ ← 暂停执行 │ - 局部变量:args, a=1 ├─────────────────┤ │ │ └─────────────────┘
◾4. methodA()调用methodB():methodB栈帧入栈
methodA中执行methodB(x + b)(计算得1+2=3),创建 **methodB栈帧 ** 压入栈顶:- 局部变量:
y=3(接收methodA传来的结果)、c=3; - 返回地址:
methodA中调用methodB的下一行代码位置。
- 局部变量:
Java栈 ┌─────────────────┐ │ methodB栈帧 │ ← 栈顶(当前执行方法) │ - 局部变量:y=3, c=3 │ - 返回地址:methodA的调用处 ├─────────────────┤ │ methodA栈帧 │ ← 暂停执行 │ - 局部变量:x=1, b=2 ├─────────────────┤ │ main栈帧 │ ← 暂停执行 ├─────────────────┤ │ │ └─────────────────┘
◾5. methodB()执行完毕:methodB栈帧出栈
methodB打印结果后执行完毕,其栈帧从栈顶弹出,程序回到methodA的返回地址继续执行。
Java栈 ┌─────────────────┐ │ methodA栈帧 │ ← 栈顶(恢复执行) │ - 局部变量:x=1, b=2 ├─────────────────┤ │ main栈帧 │ ├─────────────────┤ │ │ └─────────────────┘
◾6. methodA()执行完毕:methodA栈帧出栈
methodA继续执行剩余代码(无更多操作),执行完毕后栈帧弹出,程序回到main的返回地址。
Java栈 ┌─────────────────┐ │ main栈帧 │ ← 栈顶(恢复执行) │ - 局部变量:args, a=1 ├─────────────────┤ │ │ └─────────────────┘
◾7. main()执行完毕:main栈帧出栈
main方法执行完毕,栈帧弹出,Java 栈为空,程序结束。
Java栈 ┌─────────────────┐ │ │ ← 栈为空 │ │ └─────────────────┘
🔹 栈帧的核心组成(以上述例子为例)
每个栈帧包含 3 部分关键信息:
- 局部变量表:存储方法的参数和局部变量(如
methodB中的y=3、c=3)。 - 操作数栈:执行字节码指令时的临时数据区(如计算
x + b时,会先将x和b压入操作数栈,执行加法后弹出结果)。 - 返回地址:方法执行完后回到调用者的哪个位置(如
methodB执行完回到methodA的调用处)。
🔹 Java 栈的关键特性
- 线程私有:每个线程有独立的 Java 栈,
main线程的栈和其他线程的栈互不干扰。 - 自动管理:栈帧的入栈 / 出栈由 JVM 自动完成,无需手动操作。
- 内存溢出风险:如果方法调用链过深(如递归调用无终止条件),会导致栈帧过多,触发
StackOverflowError(栈溢出)。
在 Java 中,每个线程都会有一个独立的 Java 栈。这是 Java 内存模型的重要特性,主要基于以下几个原因:
🔹 保证线程执行的独立性
- 方法调用与局部变量隔离:Java 栈用于存储线程执行时的方法调用栈帧。每个线程在执行方法时,都会创建相应的栈帧,并将其压入自己的 Java 栈中。例如,线程 A 调用方法
methodA,会在自己的 Java 栈中创建methodA的栈帧;线程 B 调用methodA时,也会在自己的 Java 栈中创建独立的methodA栈帧。每个栈帧中存储了方法的局部变量、操作数栈以及方法返回地址等信息。
假设我们有一个Calculator类,包含一个add方法:
public class Calculator {
public int add(int a, int b) {
int result = a + b;
return result;
}
}
当线程 A 和线程 B 同时调用add方法时,线程 A 会在自己的 Java 栈中创建add方法的栈帧,其中的局部变量result只属于线程 A;线程 B 同样在自己的 Java 栈中创建独立的add方法栈帧,其局部变量result也只属于线程 B,两个线程的执行互不干扰。
- 执行流程隔离:每个线程的方法调用顺序和执行状态是独立的。例如,线程 A 在执行一系列方法
method1 -> method2 -> method3时,其 Java 栈会按照这个顺序依次压入和弹出栈帧;而线程 B 可能在执行method4 -> method5,有自己独立的栈帧操作顺序。这保证了每个线程都能按照自己的逻辑顺序执行方法,不会受到其他线程执行流程的影响。
🔹 支持线程的并发执行
- 快速切换与恢复:当操作系统进行线程调度时,需要快速切换线程的执行上下文。由于每个线程有独立的 Java 栈,保存了线程执行的当前状态(如当前方法调用到哪一步、局部变量的值等),所以可以很方便地保存当前线程的状态并恢复另一个线程的状态。比如,线程 A 在执行过程中被暂停,操作系统将其 Java 栈中的相关信息保存起来,然后切换到线程 B 执行,当再次切换回线程 A 时,根据保存的信息恢复线程 A 的 Java 栈状态,线程 A 就可以继续从暂停的地方执行,实现线程的并发执行。
- 避免数据冲突:如果多个线程共享同一个 Java 栈,那么在并发执行时,就会出现局部变量和方法调用顺序混乱的情况,导致数据冲突和程序逻辑错误。而独立的 Java 栈可以确保每个线程的执行数据和执行流程都是私有的,从而避免了这些问题,使得多线程程序能够正确、稳定地运行。
🔹 线程的并发执行的例子
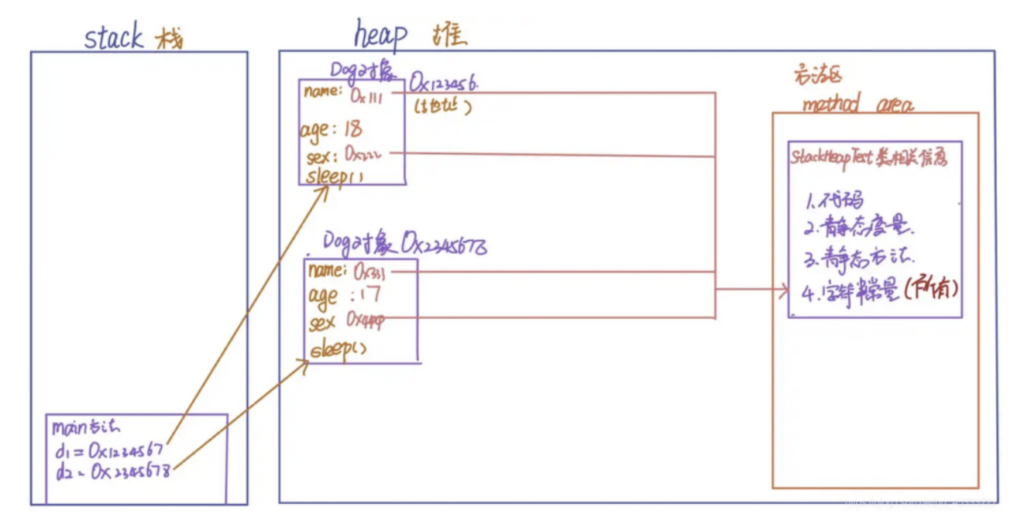
在 Java 中,堆(Heap) 和栈(Stack,这里特指线程栈) 是两种不同的内存区域,用途和特性完全不同。我们可以用 “仓库” 和 “工作台” 的类比来理解,再结合代码例子具体说明。
- 堆(Heap):
相当于一个大型公共仓库,所有工人(线程)都可以访问。里面存放的是 “大件货物”(对象实例),比如生产好的家具、电器,这些货物可以被多个工人共享。仓库的空间很大,但找东西(访问数据)相对慢一点。 - 栈(Stack):
每个工人(线程)都有自己专属的工作台,互不干扰。工作台上临时堆放的是 “当前处理的工具和材料”(局部变量、方法调用信息),比如工人正在用的螺丝刀、待组装的零件。工作台空间小但存取快,工人离开(线程结束)后,工作台会被清理。
class Book {
String name;
int borrowCount;
public Book(String name) {
this.name = name;
this.borrowCount = 0;
}
}
class StudentThread extends Thread {
private String studentName;
private Book book; // 接收外部传入的共享对象
// 构造方法接收共享的Book对象
public StudentThread(String name, Book book) {
this.studentName = name;
this.book = book; // 多个线程传入同一个Book实例
}
public void borrowBook() {
int currentCount = book.borrowCount;
book.borrowCount = currentCount + 1;
System.out.println(studentName + "借阅了《" + book.name + "》,当前借阅次数:" + book.borrowCount);
}
@Override
public void run() {
borrowBook(); // 操作共享的Book对象
}
}
public class HeapAndStackDemo {
public static void main(String[] args) {
// 1. 在外部创建一个共享的Book对象(存于堆中)
Book sharedBook = new Book("Java编程思想");
// 2. 两个线程传入同一个共享对象
new StudentThread("小明", sharedBook).start();
new StudentThread("小红", sharedBook).start();
}
}
# 注:由于线程调度顺序可能不同,结果也可能是小红先执行,但最终borrowCount会累计到 2,体现共享性。 小明借阅了《Java编程思想》,当前借阅次数:1 小红借阅了《Java编程思想》,当前借阅次数:2
内存示意图:
堆(共享区域):
┌─────────────────────────┐
│ Book对象 │
│ name: "Java入门" │
│ borrowCount: 2 │ ← 被两个线程共同修改
└─────────────────────────┘
↑
│
线程A(小明)的栈: 线程B(小红)的栈:
┌─────────────────┐ ┌─────────────────┐
│ studentName: "小明" │ studentName: "小红" │
│ book: 堆中对象地址 │ book: 堆中对象地址 │
│ borrow()调用信息 │ borrow()调用信息 │
│ current: 0(临时值) │ current: 1(临时值) │
└─────────────────┘ └─────────────────┘
4. 程序计数器(Program Counter)🔖
⭐ 程序计数器(Program Counter Register)是 Java 虚拟机(JVM)运行时数据区中一块较小的内存区域,属于线程私有。它在 Java 程序执行过程中扮演着至关重要的角色,下面将从其作用、工作原理、与其他组件的交互以及特殊情况等方面详细介绍:
🔹 作用
- 记录执行位置:程序计数器用于记录当前线程所执行的字节码指令的地址。简单来说,它就像是一个 “指针”,指向了 Java 方法字节码流中的下一条需要执行的指令。在 Java 程序运行时,执行引擎会根据程序计数器的值来获取下一条要执行的字节码指令,从而保证程序能够按照既定的顺序依次执行代码。
- 支持线程切换和恢复:在多线程环境下,CPU 需要在多个线程之间进行快速切换以实现并发执行。当一个线程的执行被暂停时(例如因为时间片用完或者等待某个资源),JVM 会保存该线程的程序计数器的值。当该线程再次被调度执行时,JVM 会恢复程序计数器的值,使线程能够从暂停的位置继续执行,确保线程执行的连续性和正确性。
🔹 工作原理
- 字节码执行导航:Java 源文件经过编译后会生成字节码文件,字节码文件中的指令是按照一定顺序排列的。当一个 Java 方法被执行时,程序计数器会被初始化为该方法字节码的第一条指令的地址。然后,在方法执行过程中,每执行完一条字节码指令,程序计数器的值就会自动递增,指向下一条待执行的字节码指令。
- 多线程场景下的变化:每个线程都有自己独立的程序计数器,这是因为每个线程都有独立的执行路径和执行状态。当线程 A 在执行某个方法时,线程 B 可能在执行另一个方法,它们各自的程序计数器分别记录着自己方法的执行进度。当线程 A 被暂停,线程 B 开始执行时,线程 A 的程序计数器会被保存起来,线程 B 的程序计数器开始发挥作用,记录线程 B 的执行位置;当线程 A 再次被调度执行时,会恢复之前保存的程序计数器的值,继续从暂停的地方执行。
🔹 与其他 JVM 组件的交互
- 与 Java 栈的协作:程序计数器与 Java 栈紧密配合,共同完成方法的执行。在方法调用时,会在 Java 栈中创建相应的栈帧,栈帧中包含了方法的局部变量、操作数栈等信息。程序计数器记录着当前执行的字节码指令,这些指令会操作栈帧中的局部变量和操作数栈。例如,字节码指令可能会从局部变量表中加载变量到操作数栈,或者将操作数栈中的结果存储到局部变量表中,而程序计数器则负责指示这些操作的执行顺序。
- 与执行引擎的交互:执行引擎是 JVM 中负责执行字节码指令的组件,它会根据程序计数器的值从字节码文件中获取下一条要执行的指令,并对指令进行解释执行或即时编译(JIT)后执行。可以说,程序计数器为执行引擎提供了执行的方向,是执行引擎执行字节码指令的 “导航仪”。
🔹 特殊情况
- 本地方法执行时:如果线程正在执行的是本地方法(即使用
native关键字修饰的方法,这些方法的实现是由非 Java 语言,如 C 或 C++ 编写的),那么程序计数器的值为未定义(undefined)。这是因为本地方法不产生字节码,不存在字节码指令序列,所以程序计数器无法记录其执行位置。 - 异常处理中的作用:当 Java 程序发生异常时,JVM 会根据异常类型和异常处理机制进行相应的处理。在异常处理过程中,程序计数器的值可能会发生变化,例如跳转到异常处理代码的起始位置,以执行相应的异常处理逻辑。
程序计数器虽然是 JVM 运行时数据区中一块相对较小的内存区域,但它对于 Java 程序的正确执行起着不可或缺的作用。它就像一个精准的 “指挥官”,指引着程序的执行流程,确保每个线程都能有条不紊地执行代码,尤其是在多线程环境下,保障了线程之间的并发执行和快速切换。
5. 本地方法栈(Native Method Stack)🔖
⭐ 本地方法栈(Native Method Stack)是 Java 虚拟机(JVM)为执行本地方法(Native Method) 提供的线程私有内存区域,功能与 Java 栈类似,但专门服务于非 Java 语言实现的方法(如 C/C++ 编写的代码)。我们通过具体例子和对比,详细解释其作用和工作原理:
🔹 什么是本地方法?
本地方法是用native关键字修饰的方法,其实现不在 Java 代码中,而是由 C/C++ 等本地语言编写,编译为机器码后嵌入 JVM 或动态链接库中。例如:
public class NativeDemo {
// 声明本地方法(无Java实现)
public native void callNativeMethod();
static {
// 加载包含本地方法实现的动态链接库(如Windows的.dll、Linux的.so)
System.loadLibrary("NativeImpl");
}
public static void main(String[] args) {
new NativeDemo().callNativeMethod();
}
}
callNativeMethod()是本地方法,Java 代码只声明了它的存在,具体实现由NativeImpl库中的 C 代码完成。- 当 Java 线程调用这个方法时,JVM 会切换到本地方法栈执行。
🔹 本地方法栈的工作流程(结合例子)
假设callNativeMethod()的 C 语言实现如下(简化版):
// NativeImpl.c
#include <jni.h>
#include <stdio.h>
// JNI规范要求的方法名格式:Java_类名_方法名
JNIEXPORT void JNICALL Java_NativeDemo_callNativeMethod(JNIEnv *env, jobject obj) {
printf("执行C语言实现的本地方法\n");
localCFunction(); // 调用另一个本地函数
}
// 本地函数(仅C语言内部调用)
void localCFunction() {
printf("执行本地辅助函数\n");
}
当 Java 线程执行callNativeMethod()时,本地方法栈的变化过程如下:
◾1. 调用本地方法前:Java 栈正常工作
main方法在 Java 栈中执行,调用callNativeMethod()前,Java 栈状态:- 本地方法栈此时为空。
Java栈(线程私有) ┌─────────────────┐ │ main栈帧 │ ← 栈顶:执行到调用callNativeMethod() └─────────────────┘
◾2. 进入本地方法:本地方法栈压栈
- JVM 检测到
callNativeMethod()是本地方法,暂停 Java 栈执行,切换到本地方法栈:- 创建 **
Java_NativeDemo_callNativeMethod栈帧 **,压入本地方法栈(记录 C 方法的参数、局部变量、返回地址)。 - 参数
JNIEnv *env和jobject obj由 JVM 自动传递(用于 C 代码与 JVM 交互)。
- 创建 **
本地方法栈(线程私有) ┌─────────────────────────────┐ │ Java_NativeDemo_callNativeMethod栈帧 ← 栈顶:执行C方法 │ - 参数:env, obj │ - 局部变量:(C函数的局部变量) │ - 返回地址:Java栈中main方法的调用处 └─────────────────────────────┘ Java栈(暂停) ┌─────────────────┐ │ main栈帧 │ └─────────────────┘
◾3. 本地方法调用本地函数:栈帧继续压入
- C 方法中调用
localCFunction()(纯 C 函数),本地方法栈继续压入新栈帧:
本地方法栈 ┌─────────────────────┐ │ localCFunction栈帧 ← 栈顶:执行辅助C函数 │ - 局部变量:(C函数的局部变量) │ - 返回地址:Java_NativeDemo_callNativeMethod的调用处 ├─────────────────────┤ │ Java_NativeDemo_callNativeMethod栈帧 ← 暂停 └─────────────────────┘
◾4. 本地函数执行完毕:栈帧出栈
localCFunction()执行完毕,其栈帧从本地方法栈弹出,回到Java_NativeDemo_callNativeMethod继续执行:
本地方法栈 ┌─────────────────────────────┐ │ Java_NativeDemo_callNativeMethod栈帧 ← 栈顶:恢复执行 └─────────────────────────────┘
◾5. 本地方法执行完毕:本地方法栈清空
Java_NativeDemo_callNativeMethod执行完毕,其栈帧弹出,本地方法栈为空:- JVM 切换回 Java 栈,
main方法从调用处继续执行。
- JVM 切换回 Java 栈,
本地方法栈(空) ┌─────────────────┐ │ │ └─────────────────┘ Java栈(恢复执行) ┌─────────────────┐ │ main栈帧 │ ← 栈顶:继续执行后续代码 └─────────────────┘
🔹 本地方法栈与 Java 栈的对比
| 对比维度 | 本地方法栈(Native Method Stack) | Java 栈(Java Stack) |
|---|---|---|
| 服务对象 | 本地方法(C/C++ 等实现) | Java 方法(字节码实现) |
| 栈帧内容 | 存储 C 函数的参数、局部变量、返回地址 | 存储 Java 方法的局部变量、操作数栈等 |
| 指令集 | 执行本地机器码(与 CPU 架构相关) | 执行 Java 字节码(跨平台) |
| 程序计数器 | 执行本地方法时,JVM 程序计数器值为undefined(无字节码地址) | 记录 Java 字节码指令地址 |
| 溢出异常 | 可能抛出StackOverflowError(递归过深) | 同样可能抛出StackOverflowError |
🔹 本地方法栈的实际应用场景
- JDK 底层功能:许多 JDK 核心方法(如
System.currentTimeMillis()、Thread.sleep())的底层实现依赖本地方法,执行时会使用本地方法栈。 - 跨语言调用:当 Java 需要调用操作系统 API(如文件操作、网络通信)或硬件驱动时,通过本地方法栈衔接 Java 代码与本地代码。
- 性能敏感场景:对性能要求极高的模块(如加密算法、图形渲染)可通过本地方法实现,本地方法栈负责管理这些代码的执行流程。
本地方法栈是 JVM 连接 Java 世界与本地代码的 “桥梁”,其工作原理与 Java 栈类似(先进后出、线程私有),但专门用于执行非 Java 语言实现的方法。它的存在让 Java 既能保持跨平台特性,又能灵活调用底层系统资源,是 JVM 体系中不可或缺的组成部分。
6. 类加载子系统(Class Loading Subsystem)🔖
⭐ 类加载子系统(Class Loading Subsystem)是 Java 虚拟机(JVM)的核心组成部分,负责将字节码文件(.class)加载到内存,并对其进行验证、准备、解析等处理,最终形成可被 JVM 直接使用的运行时数据结构。它是连接 Java 源代码编译后字节码与 JVM 执行引擎的关键环节。
- 作用:加载
.class文件到 JVM,解析成方法区的类元数据。 - 流程:
- 从文件系统、网络等位置读取
.class文件。 - 通过 “加载 → 链接(验证、准备、解析) → 初始化” 过程,最终在方法区生成类的元数据。
- 从文件系统、网络等位置读取
类加载子系统是 JVM 将字节码转换为可执行代码的 “翻译官”,通过 “加载→验证→准备→解析→初始化” 五个阶段确保类的合法性和正确性,而类加载器(尤其是双亲委派模型)则是实现这一过程的核心机制。理解类加载子系统,有助于深入掌握 Java 的动态性(如反射、动态代理)和性能优化(如类加载优化)。
7.执行引擎(Execution Engine)🔖
⭐ 执行引擎(Execution Engine)是 Java 虚拟机(JVM)的 “心脏”,负责将字节码(.class 文件中的指令)转换为机器码并执行,是连接 Java 代码与底层硬件的关键组件。它的性能直接决定了 Java 程序的运行效率,下面从核心功能、工作原理、实现方式等方面详细解释:
🔹 执行引擎的核心功能
执行引擎的核心任务是执行字节码指令,具体包括:
- 从方法区读取类的字节码指令;
- 将字节码转换为 CPU 可识别的机器码;
- 控制指令的执行顺序(如分支、循环、方法调用);
- 管理操作数栈、局部变量表等运行时数据;
- 处理异常、同步(synchronized)等特殊逻辑。
简单说,执行引擎就像 “翻译兼执行者”:把 Java 字节码(跨平台的 “中间语言”)翻译成机器能懂的 “方言”(机器码),并按顺序执行。
🔹 字节码与执行引擎的关系
Java 源代码编译后生成字节码(非机器码),字节码是一种与平台无关的指令集(如iconst_1表示将整数 1 压入栈,iadd表示整数加法)。例如,下面的 Java 代码:
public static int add(int a, int b) {
return a + b;
}
编译后的字节码指令为:
0: iload_0 // 加载第一个参数a到操作数栈 1: iload_1 // 加载第二个参数b到操作数栈 2: iadd // 弹出栈顶两个整数相加,结果压栈 3: ireturn // 返回栈顶整数
执行引擎的工作就是解析并执行这些指令,最终完成加法运算。
🔹 执行引擎的实现方式
为了平衡跨平台性和执行效率,现代 JVM(如 HotSpot、OpenJ9)的执行引擎通常采用混合执行策略,主要包括三种方式:
◾1.解释执行(Interpretation)
- 原理:逐条读取字节码指令,实时翻译成机器码并执行(“边翻译边执行”)。
- 过程:
执行引擎内置 “解释器”,对字节码指令逐个解析(如遇到iadd就调用对应的加法函数),直接操作 Java 栈的局部变量表和操作数栈。 - 优点:启动快(无需提前编译)、内存占用低,适合短时间运行的程序或代码片段。
- 缺点:执行效率低(每条指令都要重复翻译),尤其是频繁执行的代码(热点代码)。
◾2.即时编译(Just-In-Time Compilation,JIT)
- 原理:将频繁执行的字节码(热点代码)提前编译为机器码并缓存,后续直接执行机器码(“一次翻译,多次执行”)。
- 过程:
- JVM 内置 “JIT 编译器”(如 HotSpot 的 C1、C2 编译器),通过 “热点探测器” 识别频繁执行的方法或循环(如执行次数超过阈值的代码)。
- 对热点代码进行深度优化(如常量折叠、循环展开、方法内联等),编译为高效机器码,存储在方法区的 “代码缓存” 中。
- 后续执行该代码时,直接调用缓存的机器码,跳过解释过程。
- 优点:执行效率高(接近原生代码),适合长时间运行的程序(如服务器应用)。
- 缺点:启动慢(需要时间编译)、内存占用高(缓存机器码)。
◾3.混合模式(Mixed Mode)
- 原理:结合解释执行和 JIT 编译的优势 —— 非热点代码用解释执行快速启动,热点代码用 JIT 编译优化执行效率。
- 现状:现代 JVM 默认启用混合模式(可通过
-Xint强制解释执行,-Xcomp强制 JIT 编译)。