Linux 网络虚拟化的核心技术主要是网络命名空间和各种虚拟网络设备,如稍后介绍的 Veth、Linux Bridge、TUN/TAP 等。这些虚拟设备由代码实现,完全模拟物理设备的功能。
近年来广泛应用的容器技术,正是基于这些虚拟网络设备,模拟物理设备之间协作方式,将各个独立的网络命名空间连接起来,构建出不受物理环境限制的网络架构,实现容器之间、容器与宿主机之间,甚至跨数据中心的动态网络拓扑。
网络命名空间
从 Linux 内核 2.4.19 版本开始,逐步集成了多种命名空间技术,以实现对各类资源的隔离。其中,网络命名空间(Network Namespace)是最为关键的一种,也是容器技术的核心。
网络命名空间允许 Linux 系统内创建多个独立的网络环境,每个环境拥有独立的网络资源,如防火墙规则、网络接口、路由表、ARP 邻居表及完整的网络协议栈。当进程运行在某个网络命名空间内时,就像独享一台物理主机。
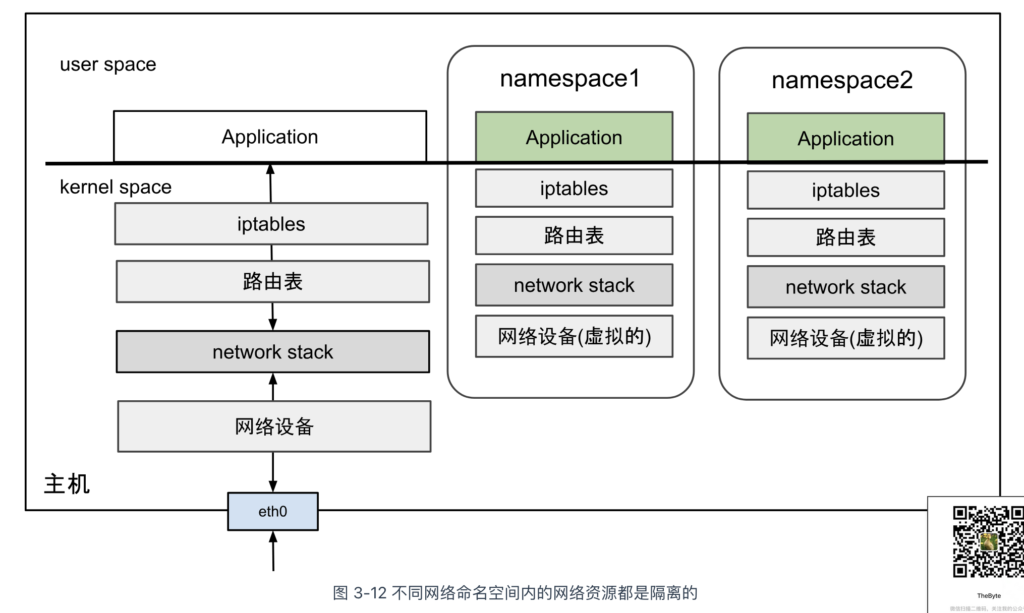
在 Linux 系统 中,ip 工具的子命令 netns 集成了网络命名空间的增、删、查、改等功能。接下来,笔者将使用 ip 命令演示如何操作网络命名空间,帮助你加深理解。
首先,创建一个名为 ns1 的网络命名空间。命令如下所示:
$ ip netns add ns1
查询 ns1 网络命名空间内的网络设备信息。可以看到,由于没有进行任何配置,该网络命名空间内只有一个名为 lo 的本地回环设备,且设备状态为 DOWN。
$ ip netns exec ns1 ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
查看 ns1 网络命名空间下的 iptables 规则配置。可以看到,由于这是一个初始化的网络命名空间,因此 iptables 规则为空,并没有任何配置。
$ ip netns exec ns1 iptables -L -n Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination
不难看出,不同的网络命名空间默认相互隔离,也无法直接通信。如果它们需要与外界(其他网络命名空间或宿主机)建立连接,该如何实现呢?
我们先看看物理机是怎么操作的,一台物理机如果要想与外界进行通信,那得插入一块网卡,通过网线连接到以太网交换机,加入一个局域网内。被隔离的网络命名空间如果想与外界进行通信,就需要利用到稍后介绍的各类虚拟网络设备。也就是,在网络命名空间里面插入“虚拟网卡”,然后把“网线”的另一头桥接到“虚拟交换机”中。
没错,这些操作完全和物理环境中的配置局域网一样,只不过全部是虚拟的、用代码实现的而已。
虚拟网络设备 TUN 和 TAP
TUN 和 TAP 是 Linux 内核自 2.4.x 版本引入的虚拟网卡设备,专为用户空间(user space)与内核空间(kernel space)之间的数据传输而设计。两者的主要区别如下:
- TUN 设备:工作在网络层(Layer 3),用于处理 IP 数据包。它模拟一个网络层接口,使用户空间程序能够直接收发 IP 数据包;
- TAP 设备:工作在数据链路层(Layer 2),用于处理以太网帧。与 TUN 设备不同,TAP 设备传输完整的以太网帧(包括数据链路层头部),使用户空间程序可以处理原始以太网帧。
Linux 系统中,内核空间和用户空间之间数据传输有多种方式,字符设备文件是其中一种。
TUN/TAP 设备对应的字符设备文件为 /dev/net/tun。当用户空间的程序打开(open)字符设备文件时,同时,TUN/TAP 的字符设备驱动会创建并注册相应的虚拟网卡,默认命名为 tunX 或 tapX。随后,用户空间程序读写(read/write)该文件描述符,就可以和内核网络栈进行数据交互了。
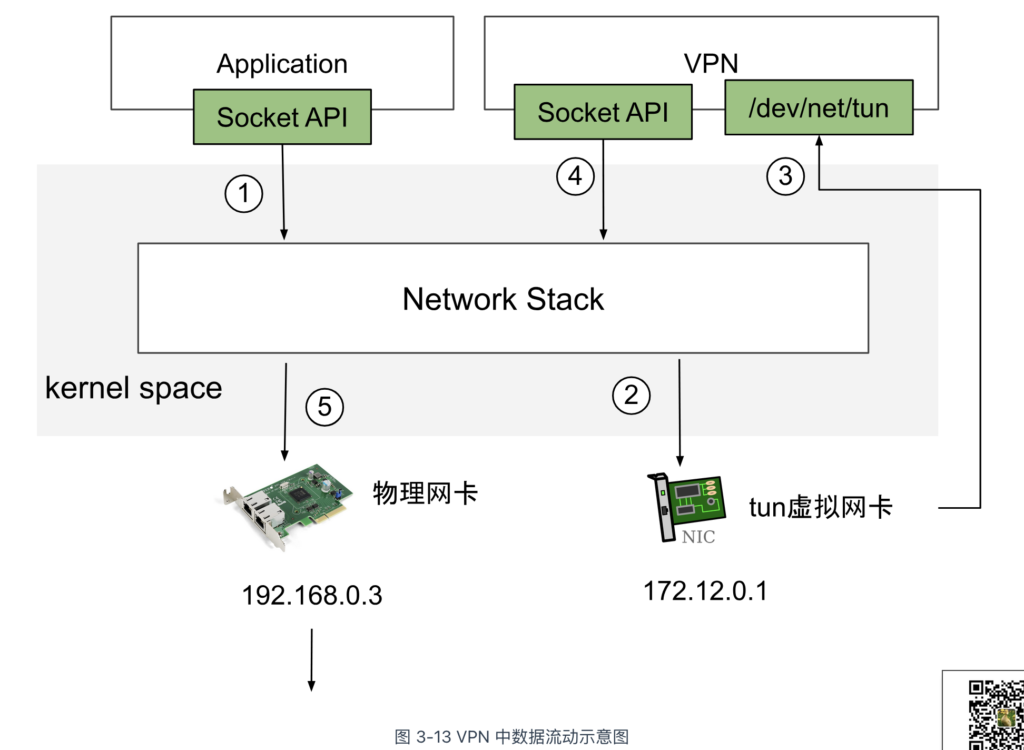
如图 3-13 所示,下面以 TUN 设备构建 VPN 隧道为例,说明其工作原理。如下:
- 首先,一个普通的用户程序发起一个网络请求;
- 接着,数据包进入内核协议栈,并路由至 tun0 设备。路由规则如下:
$ ip route show default via 172.12.0.1 dev tun0 // 默认流量经过 tun0 设备 192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.3
- tun0 设备的字符设备文件 /dev/net/tun 由 VPN 程序打开。所以,用户程序发送的数据包不会直接进入网络,而是被 VPN 程序读取并处理。
- VPN 程序对数据包进行封装操作,封装(Encapsulation)是指在原始数据包外部包裹新的数据头部,就像将一个盒子放在另一个盒子中一样。
- 最后,处理后的数据包再次写入内核网络栈,并通过 eth0(即物理网卡)发送到目标网络。
封装数据包以构建网络隧道,是实现虚拟网络的常见方式。例如,在本书第七章介绍的容器网络插件 Flannel 早期版本中,曾使用 TUN 设备来实现容器间的虚拟网络通信。但是,TUN 设备的数据传输需经过两次协议栈,并涉及多次封包与解包操作,导致了很大的性能损耗。这也是 Flannel 后来弃用 TUN 设备的主要原因。
虚拟网卡 Veth
Linux 内核 2.6 版本支持网络命名空间的同时,也提供了专门的虚拟网卡 Veth(Virtual Ethernet,虚拟以太网网卡)。
Veth 的核心原理是“反转数据传输方向”,即在内核中,将发送端的数据包转换为接收端的新数据包,并重新交由内核网络协议栈处理。通俗的解释,Veth 就是一根带着两个“水晶头”的“网线”,从网线的一头发送数据,另一头就会收到数据。因此,Veth 也被说成是“一对设备”(Veth-Pair)。
Veth 设备的典型应用场景是连接相互隔离的网络命名空间,使它们能够进行通信。假设存在两个网络命名空间 ns1 和 ns2,其网络拓扑结构如图 3-14 所示。接下来,笔者将通过实际操作演示 Veth 设备如何在网络命名空间之间建立通信,帮助你加深理解。
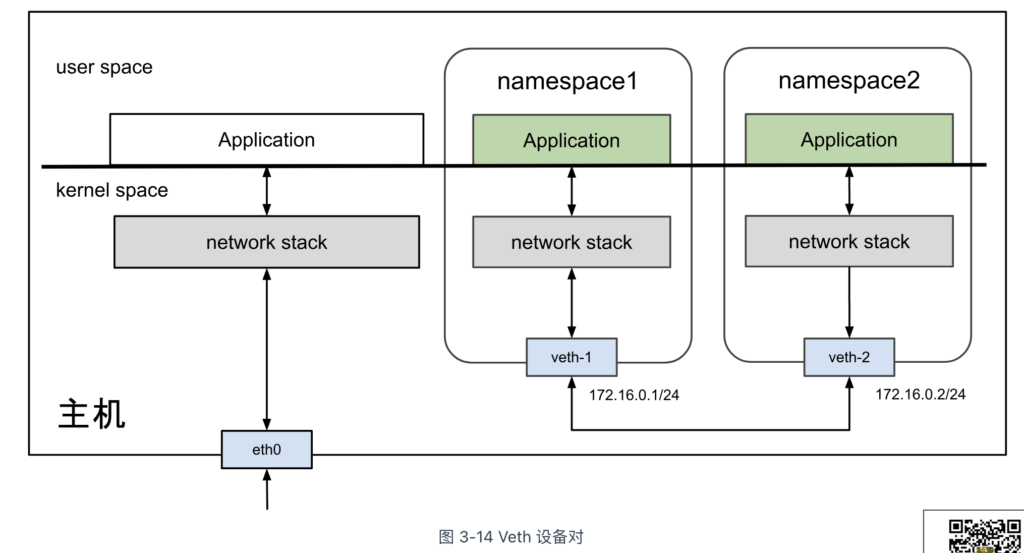
首先,使用以下命令创建一对 Veth 设备,命名为 veth1 和 veth2。该命令会生成一对虚拟以太网设备,它们之间形成点对点连接,即数据从 veth1 发送后,会直接出现在 veth2 上,反之亦然。
$ ip link add veth1 type veth peer name veth2
接下来,我们将分别将它们分配到不同的网络命名空间。
$ ip link set veth1 netns ns1 $ ip link set veth2 netns ns2
Veth 作为虚拟网络设备,具备与物理网卡相同的特性,因此可以配置 IP 和 MAC 地址。接下来,我们为 Veth 设备分配 IP 地址,使其处于同一子网 172.16.0.0/24,然后激活设备。
# 配置命名空间1 $ ip netns exec ns1 ip link set veth1 up $ ip netns exec ns1 ip addr add 172.16.0.1/24 dev veth1 # 配置命名空间2 $ ip netns exec ns2 ip link set veth2 up $ ip netns exec ns2 ip addr add 172.16.0.2/24 dev veth2
Veth 设备配置 IP 后,每个网络命名空间都会自动生成相应的路由信息。如下所示:
$ ip netns exec ns1 ip route 172.16.0.0/24 dev veth1 proto kernel scope link src 172.16.0.1
上述路由配置表明,所有属于 172.16.0.0/24 网段的数据包都会经由 veth1 发送,并在另一端由 veth2 接收。在 ns1 中执行 ping 测试,可以验证两个网络命名空间已经成功互通了。
$ ip netns exec ns1 ping -c10 172.16.0.2 PING 172.16.0.2 (172.16.0.2) 56(84) bytes of data. 64 bytes from 172.16.0.2: icmp_seq=1 ttl=64 time=0.121 ms 64 bytes from 172.16.0.2: icmp_seq=2 ttl=64 time=0.063 ms
最后,虽然 Veth 设备模拟网卡直连的方式解决了两个容器之间的通信问题,但面对多个容器间通信需求,如果只用 Veth 设备的话,事情就会变得非常麻烦。让每个容器都为与它通信的其他容器建立一对专用的 Veth 设备,根本不切实际。此时,就迫切需要一台虚拟化交换机来解决多容器之间的通信问题,这正是笔者前面多次提到的 Linux bridge。
虚拟交换机 Linux Bridge
在物理网络中,交换机用于连接多台主机,组成局域网。在 Linux 网络虚拟化技术中,同样提供了物理交换机的虚拟实现,即 Linux Bridge(Linux 网桥,也称虚拟交换机)。
Linux Bridge 作为虚拟交换机,其功能与物理交换机类似。将多个网络接口(如物理网卡 eth0、虚拟接口 veth、tap 等)桥接后,它们的通信方式与物理交换机的转发行为一致。当数据帧进入 Linux Bridge 时,系统根据数据帧的类型和目的地 MAC 地址执行以下处理:
- 广播帧:转发到所有桥接到该 Linux Bridge 的设备。
- 单播帧:查找 FDB(Forwarding Database,地址转发表)中 MAC 地址与设备网络接口的映射记录:
- 若未找到记录,执行“洪泛”(Flooding),将数据帧发送到所有接口,并根据响应将设备的网络接口与 MAC 地址记录到 FDB 表中;
- 若找到记录,则直接将数据帧转发到对应设备的网络接口。
以下是一个具体例子,展示如何使用 Linux Bridge 将两个网络命名空间连接到同一二层网络。网络拓扑如图 3-15 所示。
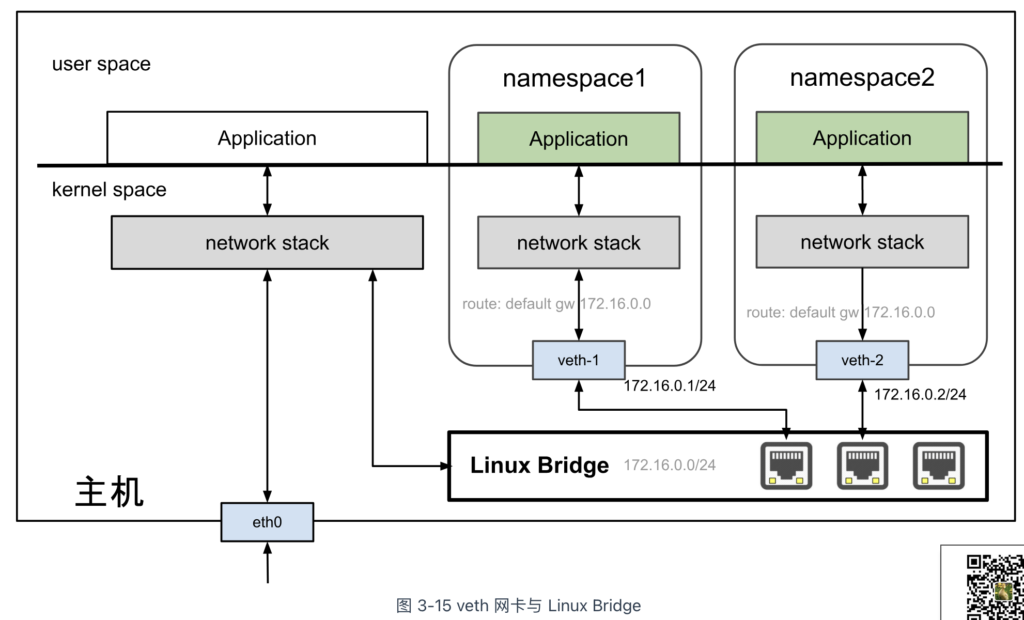
- 首先,创建一个 Linux Bridge 设备。如下命令所示,创建一个名为 br0 的虚拟交换机,并将其激活。
$ ip link add name br0 type bridge $ ip link set br0 up
- 接着,创建一对 Veth 设备,并将它们分别分配给两个命名空间。
# 创建 veth1 和 veth2 $ ip link add veth1 type veth peer name veth2 # 将 veth1 分配到 ns1 $ ip link set veth1 netns ns1 # 将 veth2 分配到 ns2 $ ip link set veth2 netns ns2
- 将 veth1 和 veth2 接入到 br0 桥接设备,从而让它们成为同一二层网络的一部分。
# 将 veth1 添加到 br0 桥接 $ ip link set dev veth1 up $ brctl addif br0 veth1 # 将 veth2 添加到 br0 桥接 $ ip link set dev veth2 up $ brctl addif br0 veth2
- 为每个命名空间中的 Veth 设备配置 IP 地址。
# 配置命名空间1中的 veth1 $ ip netns exec ns1 ip addr add 172.16.0.1/24 dev veth1 $ ip netns exec ns1 ip link set veth1 up # 配置命名空间2中的 veth2 $ ip netns exec ns2 ip addr add 172.16.0.2/24 dev veth2 $ ip netns exec ns2 ip link set veth2 up
- 最后,在 ns1 命名空间中测试与 ns2 命名空间的通信。
$ ip netns exec ns1 ping 172.16.0.2 PING 172.16.0.2 (172.16.0.2) 56(84) bytes of data. 64 bytes from 172.16.0.1: icmp_seq=1 ttl=64 time=0.153 ms 64 bytes from 172.16.0.1: icmp_seq=2 ttl=64 time=0.148 ms 64 bytes from 172.16.0.1: icmp_seq=3 ttl=64 time=0.116 ms
通过上述步骤,我们创建了一个 Linux Bridge,将两个命名空间 ns1 和 ns2 通过虚拟以太网设备连接在同一个二层网络中。这样,两个命名空间之间可以通过桥接设备直接通信,实现在同一局域网内的网络互通。
需要补充的是,Linux Bridge 本质上是 Linux 系统中的虚拟网络设备,具备网卡特性,能够配置 MAC 和 IP 地址。从主机的角度来看,配置了 IP 地址的 Linux Bridge 设备就相当于一块“网卡”,能够参与数据包的 IP 路由。因此,当网络命名空间的默认网关设置为 Linux Bridge 的 IP 地址时,原本隔离的网络命名空间便能够与主机进行通信。
实现容器与主机之间的互通,是容器间通信的关键环节。
虚拟网络通信技术 VXLAN
基于物理设备实现的“原生”网络拓扑结构相对固定,很难跟得上云原生时代下系统频繁变动的频率。例如,容器的动态扩缩容、集群跨数据中心迁移等等,都要求网络拓扑随时做出调整。正因为如此,软件定义网络(Software Defined Networking,SDN)的需求变得前所未有的迫切。
SDN 的核心思想是在现有物理网络之上构建一层虚拟网络,通过解耦控制平面(操作系统和网络控制软件)与数据平面(物理设备和通信协议),将网络服务从底层硬件中抽象出来,使其能够通过软件编程直接控制。
SDN 网络模型如图 3-16 所示,它由两个部分组成。
- Underlay 网络(底层网络):由路由器、交换机等硬件设备组成的物理网络,负责底层数据传输。
- Overlay 网络(覆盖网络):基于网络虚拟化技术构建在 Underlay 之上的逻辑网络,实现虚拟机、容器等计算资源之间的互联。
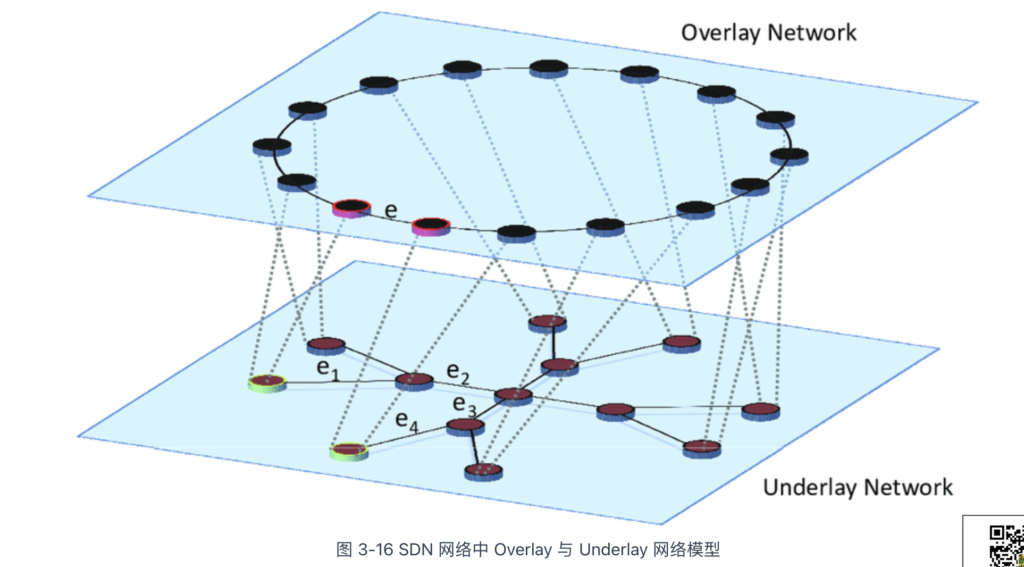
SDN 的发展早于云原生十余年,在此过程中涌现出多种 Overlay 网络实现方案,如 Geneve(Generic Network Virtualization Encapsulation)、VXLAN(Virtual Extensible LAN)、STT(Stateless Transport Tunneling)等。这些技术本质上都是隧道技术,即通过“在现有物理网络上封装数据包,创建虚拟网络”。
在虚拟网络中,容器无需关注底层物理网络的路由规则,而物理网络也无需针对容器 IP 进行专门的路由配置。因此,以 VXLAN 为代表的 Overlay 网络,作为一种无需修改底层网络即可实现容器互联的方案,快速在容器领域铺开了。
学习 VXLAN 之前,有必要充分了解一些物理网络通信的基本原理。接下来,笔者将先介绍 VXLAN 的前身 VLAN(Virtual Local Area Network,虚拟局域网)技术。
虚拟局域网 VLAN
在以太网通信中,数据帧必须包含目标 MAC 地址才能正常传输。因此,计算机在通信前通常会先广播 ARP 请求,以获取目标 MAC 地址。但是,当一个广播域内设备非常多时,ARP、DHCP、RIP 等机制会产生大量的广播帧,很容易形成广播风暴。因此,VLAN 的核心职责是划分广播域,使每个 VLAN 形成独立的广播域,从逻辑上隔离同一物理网络中的设备。
举一个具体的例子。假设一个原始广播域使用网段 172.16.0.0/16,其默认情况下可以容纳 65,536 个 IP 地址(不包括保留地址)。若不进行划分,所有设备共享同一广播域,ARP 等广播流量可能引发严重的网络拥塞。如果将 172.16.0.0/16 划分为 255 个子网,每个子网对应 172.16.1.0/24、172.16.2.0/24、172.16.3.0/24,直到 172.16.255.0/24,每个子网的 VLAN ID 依次为 1、2、3 … 255。这样,每个 VLAN 拥有独立的广播域,理论上可容纳 254 台终端,广播风暴的影响指数级下降。
VLAN 划分子网的方式是在以太帧报头中添加 VLAN Tag,使广播仅在相同 VLAN Tag 的设备间生效。支持 VLAN 的交换机可识别帧内的 VLAN ID,确保数据包仅在相同 VLAN 内转发。
VLAN 划分子网虽然能有效控制广播风暴,但在既需要隔离又希望部分主机互通的场景下,仅划分 VLAN 还不够,还需建立跨 VLAN 访问的通道。由于不同 VLAN 之间完全隔离,广播域不重叠,它们的通信必须依赖三层路由设备。
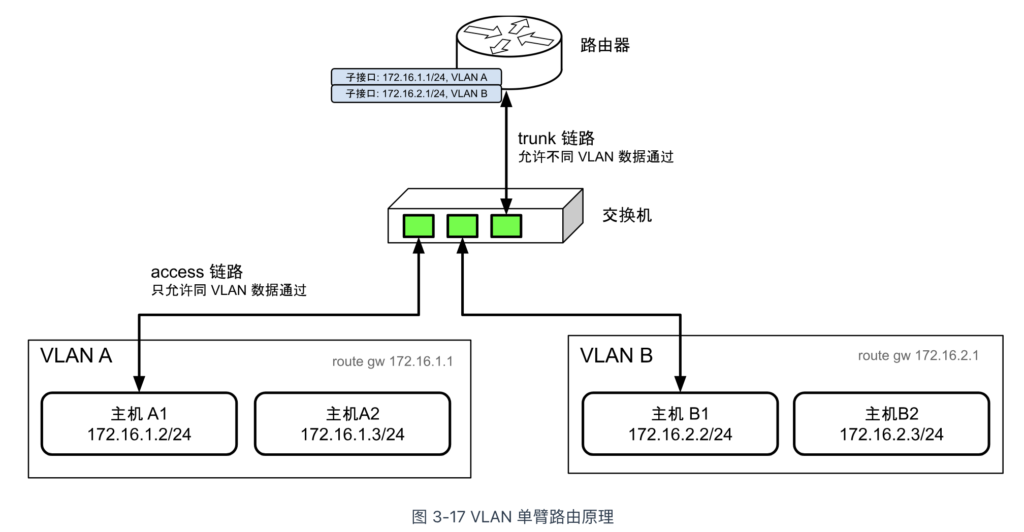
最简单的三层路由模式是通过单臂路由实现的。其网络拓扑如图 3-17 所示,路由器与交换机之间通过一条线路连接,称为 Trunk 链路。与之相对,主机与交换机之间的链路称为 Access 链路。Trunk 链路允许任何 VLAN ID 的数据包通过。当需要路由的数据包通过 Trunk 链路传输到路由器进行处理后,处理完的包会返回至交换机进行转发。所以大家给这种拓扑起了一个形象的名字 —— 单臂路由。
说白了,单臂路由就是从哪个口进去,再从哪个口出来,而不像传统网络拓扑中数据包通过不同接口进入和离开路由器。为了实现这种单臂路由模式,802.1Q 以太网规范定义了“子接口”(Sub-Interface)的概念,使得同一物理网卡可以绑定不同 VLAN 的 IP 地址。通过将各子网的默认网关配置为相应子接口的地址,路由器可以通过修改 VLAN 标签来实现不同 VLAN 之间的跨子网数据转发。
VLAN 虽然通过划分子网来解决广播风暴,但它也有明显的缺陷:
- VLAN Tag 设计缺陷:当时的网络工程师完全未料及云计算会发展得会如此普及,只设计了 12 位 bit 存储 VLAN ID,因此最多只能支持 4,094 个 VLAN。对于大型数据中心或运营商网络,这个数量远远不够,很容易造成 VLAN ID 枯竭。
- 跨数据中心通信困难:VLAN 是二层网络技术,而两个独立数据中心之间只能通过三层网络互通。这使得在云计算环境中,尤其是在业务跨多个数据中心部署时,传递 VLAN Tag 成为一种麻烦的工作。特别是在容器化环境中,一台物理机上可能运行数百个容器,每个容器都有独立的 IP 和 MAC 地址,这给路由器、交换机等设备带来了巨大的压力。
虚拟可扩展局域网 VXLAN
为了解决 VLAN 的设计缺陷,IETF 定义了 VXLAN(Virtual eXtensible Local Area Network,虚拟可扩展局域网)规范。虽然从名字上看,VXLAN 似乎是 VLAN 的一种扩展协议,但实际上,它与 VLAN 在设计理念和实现方式上有着本质的不同。
VXLAN 属于 NVO3(Network Virtualization over Layer 3,三层虚拟化网络)的标准技术规范之一,采用隧道封装技术。其基本原理是通过“封装/解封”手段,将二层(L2)以太网帧封装到四层(L4)UDP 报文中,并在三层(L3)网络中进行传输。这样,不同数据中心节点之间的通信便如同在同一广播域内进行,从而解决了传统 VLAN 面临的扩展性和跨数据中心通信的限制。
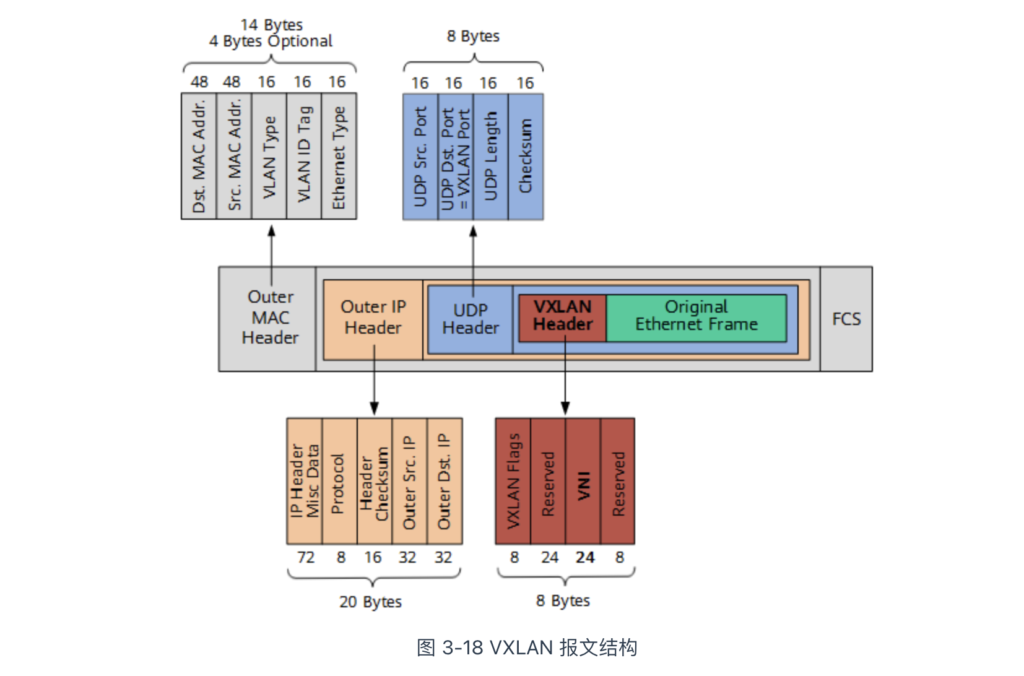
根据图 3-18,我们可以看到 VXLAN 报文如何封装原始的以太网帧(图中的 Original Layer2 Frame):
- VXLAN Header:包含 24 位的 VNI(VXLAN Network Identifier)字段,用于定义 VXLAN 网络中的不同租户,支持的最大数量为 1,677 万个。
- UDP Header:在 UDP 头中,目的端口号(图中的 VXLAN Port)固定为 4789,源端口随机分配。
- Outer IP Header:封装目的 IP 地址和源 IP 地址,这里 IP 指的是宿主机的 IP 地址。
- Outer MAC Header:封装源 MAC 地址,目的 MAC 地址,这里 MAC 地址指的是宿主机 MAC 地址。
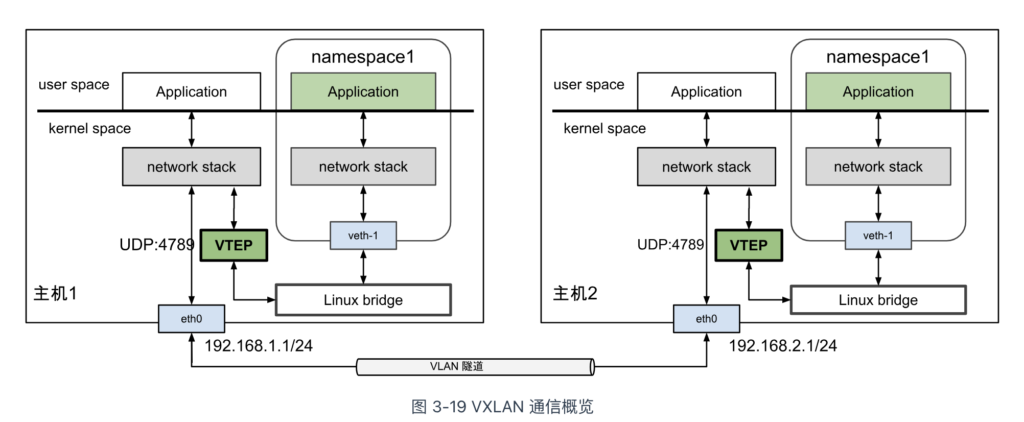
在 VXLAN 隧道网络中,负责“封装/解封”的设备被称为 VTEP 设备(VXLAN Tunnel Endpoints,VXLAN 隧道端点),在 Linux 系统中,它实际上是一个虚拟的 VXLAN 网络接口。当源服务器中的容器发送原始数据帧时,首先由起点的 VTEP 设备将其封装为 VXLAN 格式的报文,然后通过主机的 IP 网络传输到目标服务器的 VTEP 设备。目标服务器中的 VTEP 设备解封 VXLAN 报文,恢复原始数据帧,并将其转发到目标容器。
Linux 内核 3.12 版本开始支持完备的 VXLAN 技术,包括多播模式、单播模式和 IPv6 支持等功能。现在,在三层可达的网络环境中,无需专用硬件,简单配置下 Linux 系统,就可以构建 VXLAN 隧道网络。
以下是一个具体示例,展示了如何在 Linux 系统中配置 VXLAN 接口并将其与 Linux bridge 绑定。
# 创建一个 bridge $ brctl addbr br0 # 创建一个 VXLAN 接口,VNI 为 100,指定使用 eth0 作为物理接口 $ ip link add vxlan100 type vxlan id 100 dev eth0 dstport 4789 # 将 VXLAN 接口加入 bridge $ brctl addif br0 vxlan100 # 启动 bridge 和 VXLAN 接口 $ ip link set up dev br0 $ ip link set up dev vxlan100
通过上述配置,当 vxlan100 接口接收到数据包(通过 VXLAN 隧道传输而来)时:
- 首先,进行解封操作,移除 VXLAN 头部和 UDP 头部,提取原始的二层以太网帧;
- 然后,将原始二层以太网帧转发至名为 br0 的 Linux bridge,之后 Linux bridge 根据其连接的网络接口转发至某个网络命名空间。
从上述分析可以看出,VXLAN 完美弥补了 VLAN 的不足:
- 首先,VXLAN 使用 24 位的 VNI 字段(如图 3-18 所示),理论上可支持超过 1,600 万个逻辑二层网络,远超 VLAN 的 4,094 个限制;
- 其次,VXLAN 本质上构建了跨越多个物理网络的“隧道”,通过将原始 Layer 2(以太网)帧封装在 Layer 3(IP 网络)中进行传输,实现不同物理网络之间的通信,犹如处于同一个广播域。无论虚拟机或容器迁移到 VLAN B 还是 VLAN C,它们仍然处于同一个二层网络中,网络层配置无需调整。
VXLAN 具备高灵活性、可扩展性和易于管理的特点,已成为构建数据中心及容器网络的主流技术。绝大多数公有云的 VPC(虚拟私有云)及容器网络均采用 VXLAN 技术构建大型二层网络。在本书第七章的 7.6 节中,笔者将以容器网络解决方案 Flannel 的 VXLAN 模式为例,详细阐述容器网络通信的过程及原理。
小结
道家经典《庄子》中有一则庖丁解牛的故事。梁惠王因庖丁解牛的技术惊叹:“你的技术咋会高超到这种程度?”,庖丁回:“我所追求的是宰牛的道理啊,道理要比技艺更高一筹…”。
软件开发技术其实和解牛技术是相通的。当你不懂底层原理时,你只能看到表面的现象。技术精进后,达到庖丁境界时,就如同佩戴了透视镜,能洞察系统的内在脉络,理解各个模块的“有机”协作,进而对整个系统架构有个全局视野,准确把握设计与技术选型的核心。
此刻,再回顾近几年引领技术潮流的容器、服务网格、Cilium 等等,你是否体会到它们不是什么“黑科技”,只是把计算机的基本原理、方法重新组合,换种形式解决业务变化带来的新问题。