实际开发中,当业务流量过大时,为了保护下游服务,我们通常会做一些预防性的工作,今天我们就一起来聊聊限流!
为什么需要限流?
在实际应用中,每个系统或者服务都有其处理能力的极限(瓶颈),即便是微服务中有集群和分布式的夹持,也不能保证系统能应对任何大小的流量,
因此,系统为了自保,需要对处理能力范围以外的流量进行“特殊照顾”(比如,丢弃请求或者延迟处理),从而避免系统卡死、崩溃或不可用等情况,保证系统整体服务可用。
限流算法
令牌桶算法
令牌桶算法(Token Bucket Algorithm)是计算机网络和电信领域中常用的一种简单方法,用于流量整形和速率限制。它旨在控制系统在某个时间段内可以发送或接收的数据量,确保流量符合指定的速率。
令牌桶算法的核心思路:系统按照固定速度往桶里加入令牌,如果桶满则停止添加。当有请求到来时,会尝试从桶里拿走一个令牌,取到令牌才能继续进行请求处理,没有令牌就拒绝服务。示意图如下:
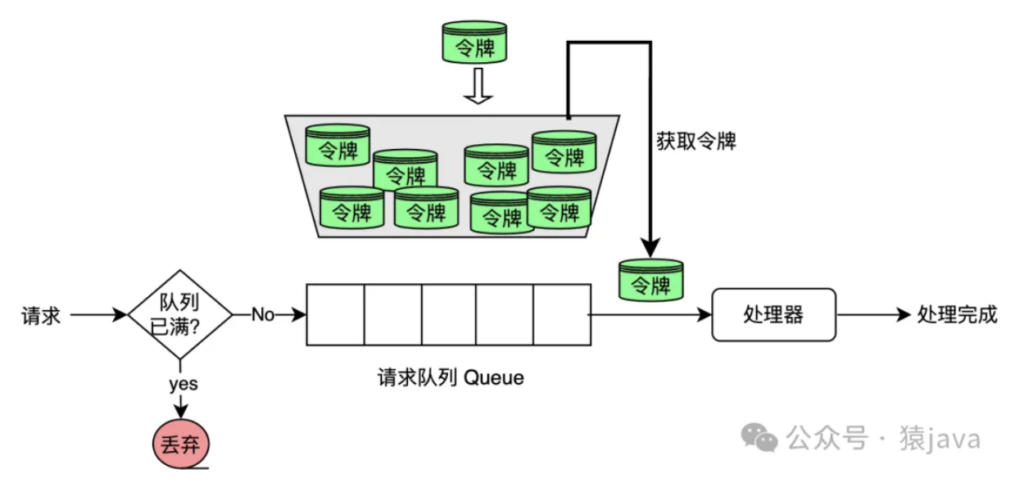
令牌桶法的几个特点:
- 令牌桶容量固定,即系统的处理能力阈值
- 令牌放入桶内的速度固定
- 令牌从桶内拿出的速度根据实际请求量而定,每个请求对应一个令牌
- 当桶内没有令牌时,请求进入等待或者被拒绝
令牌桶算法主要用于应对突发流量的场景,在 Java语言中使用最多的是 Google的 Guava RateLimiter,下面举几个例子来说明它是如何应对突发流量:
示例1
import java.util.concurrent.TimeUnit;
public class RateLimit {
public static void main(String[] args) {
RateLimiter limiter = RateLimiter.create(5); // 每秒创建5个令牌
System.out.println("acquire(5), wait " + limiter.acquire(5) + " s"); // 全部取走 5个令牌
System.out.println("acquire(1), wait " + limiter.acquire(1) + " s");// 获取1个令牌
boolean result = limiter.tryAcquire(1, 0, TimeUnit.SECONDS); // 尝试获取1个令牌,获取不到则直接返回
System.out.println("tryAcquire(1), result: " + result);
}
}
示例代码运行结果如下:
acquire(5), wait 0.0 s acquire(1), wait 0.971544 s tryAcquire(1), result: false
桶中共有 5个令牌,acquire(5)返回0 代表令牌充足无需等待,当桶中令牌不足,acquire(1)等待一段时间才获取到,当令牌不足时,tryAcquire(1)不等待直接返回。
示例2
import com.google.common.util.concurrent.RateLimiter;
public class RateLimit {
public static void main(String[] args) {
RateLimiter limiter = RateLimiter.create(5);
System.out.println("acquire(10), wait " + limiter.acquire(10) + " s");
System.out.println("acquire(1), wait " + limiter.acquire(1) + " s");
}
}
示例代码运行结果如下:
acquire(10), wait 0.0 s acquire(1), wait 1.974268 s
桶中共有 5个令牌,acquire(10)返回0,和示例似乎有点冲突,其实,这里返回0 代表应对了突发流量,但是 acquire(1)
却等待了 1.974268秒,这代表 acquire(1)的等待是时间包含了应对突然流量多出来的 5个请求,即 1.974268 = 1 + 0.974268。
为了更好的验证示例2的猜想,我们看示例3:
示例3
import com.google.common.util.concurrent.RateLimiter;
import java.util.concurrent.TimeUnit;
public class RateLimit {
public static void main(String[] args) throws InterruptedException {
RateLimiter limiter = RateLimiter.create(5);
System.out.println("acquire(5), wait " + limiter.acquire(5) + " s");
TimeUnit.SECONDS.sleep(1);
System.out.println("acquire(5), wait " + limiter.acquire(5) + " s");
System.out.println("acquire(1), wait " + limiter.acquire(1) + " s");
}
}
示例代码运行结果如下:
acquire(5), wait 0.0 s acquire(5), wait 0.0 s acquire(1), wait 0.966104 s
桶中共有 5个令牌,acquire(5)返回0 代表令牌充足无需等待,接着睡眠 1s,这样系统又可以增加5个令牌,
因此,再次 acquire(5)令牌充足返回0 无需等待,acquire(1)需要等待一段时间才能获取令牌。
漏桶算法
漏桶算法(Leaky Bucket Algorithm)的核心思路是:水(请求)进入固定容量的漏桶,漏桶的水以固定的速度流出,当水流入漏桶的速度过大导致漏桶满而直接溢出,然后拒绝请求。示意图如下:
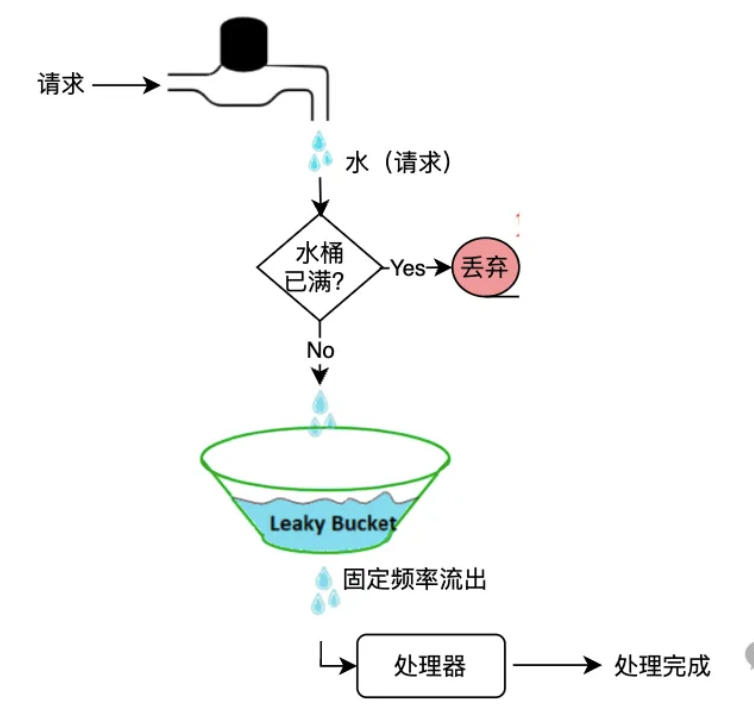
下面为一个 Java版本的漏桶算法示例:
import java.util.concurrent.*;
public class LeakyBucket {
private final int capacity; // 桶的容量
private final int rate; // 出水速率
private int water; // 漏斗中的水量
private long lastLeakTime; // 上一次漏水的时间
public LeakyBucket(int capacity, int rate) {
this.capacity = capacity;
this.rate = rate;
this.water = 0;
this.lastLeakTime = System.currentTimeMillis();
}
public synchronized boolean allowRequest(int tokens) {
leak(); // 漏水
if (water + tokens <= capacity) {
water += tokens; // 漏斗容量未满,可以加水
return true;
} else {
return false; // 漏斗容量已满,无法加水
}
}
private void leak() {
long currentTime = System.currentTimeMillis();
long timeElapsed = currentTime - lastLeakTime;
int waterToLeak = (int) (timeElapsed * rate / 1000); // 计算经过的时间内应该漏掉的水量
water = Math.max(0, water - waterToLeak); // 漏水
lastLeakTime = currentTime; // 更新上一次漏水时间
}
public static void main(String[] args) {
LeakyBucket bucket = new LeakyBucket(10, 2); // 容量为10,速率为2令牌/秒
int[] packets = {2, 3, 1, 5, 2, 10}; // 要发送的数据包大小
for (int packet : packets) {
if (bucket.allowRequest(packet)) {
System.out.println("发送 " + packet + " 字节的数据包");
} else {
System.out.println("漏桶已满,无法发送数据包");
}
try {
TimeUnit.SECONDS.sleep(1); // 模拟发送间隔
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
漏桶算法的几个特点:
- 漏桶容量固定
- 流入(请求)速度随意
- 流出(处理请求)速度固定
- 桶满则溢出,即拒绝新请求(限流)
计数器算法
计数器是最简单的限流方式,主要用来限制总并发数,主要通过一个支持原子操作的计数器来累计 1秒内的请求次数,当 秒内计数达到限流阈值时触发拒绝策略。每过 1秒,计数器重置为 0开始重新计数。比如数据库连接池大小、线程池大小、程序访问并发数等都是使用计数器算法。
如下代码就是一个Java版本的计数器算法示例,通过一个原子计算器 AtomicInteger来记录总数,如果请求数大于总数就拒绝请求,否则正常处理请求:
import java.util.concurrent.atomic.AtomicInteger;
public class CounterRateLimiter {
private final int limit; // 限流阈值
private final long windowSizeMs; // 时间窗口大小(毫秒)
private AtomicInteger counter; // 请求计数器
private long lastResetTime; // 上次重置计数器的时间
public CounterRateLimiter(int limit, long windowSizeMs) {
this.limit = limit;
this.windowSizeMs = windowSizeMs;
this.counter = new AtomicInteger(0);
this.lastResetTime = System.currentTimeMillis();
}
public boolean allowRequest() {
long currentTime = System.currentTimeMillis();
// 如果当前时间超出了时间窗口,重置计数器
if (currentTime - lastResetTime > windowSizeMs) {
counter.set(0);
lastResetTime = currentTime;
}
// 检查计数器是否超过了限流阈值
return counter.incrementAndGet() <= limit;
}
public static void main(String[] args) {
CounterRateLimiter rateLimiter = new CounterRateLimiter(3, 1000); // 每秒最多处理3个请求
for (int i = 0; i < 10; i++) {
if (rateLimiter.allowRequest()) {
System.out.println("允许请求 " + (i + 1));
} else {
System.out.println("限流,拒绝请求 " + (i + 1));
}
try {
Thread.sleep(200); // 模拟请求间隔
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
滑动窗口算法
滑动窗口算法是一种常用于限流和统计的算法。它基于一个固定大小的时间窗口,在这个时间窗口内统计请求的数量,
并根据设定的阈值来控制流量。比如,TCP协议就使用了该算法
以下是一个简单的 Java 示例实现滑动窗口算法:
import java.util.concurrent.atomic.AtomicInteger;
public class SlidingWindowRateLimiter {
private final int limit; // 限流阈值
private final long windowSizeMs; // 时间窗口大小(毫秒)
private final AtomicInteger[] window; // 滑动窗口
private long lastUpdateTime; // 上次更新窗口的时间
private int pointer; // 指向当前时间窗口的指针
public SlidingWindowRateLimiter(int limit, long windowSizeMs, int granularity) {
this.limit = limit;
this.windowSizeMs = windowSizeMs;
this.window = new AtomicInteger[granularity];
for (int i = 0; i < granularity; i++) {
window[i] = new AtomicInteger(0);
}
this.lastUpdateTime = System.currentTimeMillis();
this.pointer = 0;
}
public synchronized boolean allowRequest() {
long currentTime = System.currentTimeMillis();
// 计算时间窗口的起始位置
long windowStart = currentTime - windowSizeMs + 1;
// 更新窗口中过期的计数器
while (lastUpdateTime < windowStart) {
lastUpdateTime++;
window[pointer].set(0);
pointer = (pointer + 1) % window.length;
}
// 检查窗口内的总计数是否超过限流阈值
int totalRequests = 0;
for (AtomicInteger counter : window) {
totalRequests += counter.get();
}
if (totalRequests >= limit) {
return false; // 超过限流阈值,拒绝请求
} else {
window[pointer].incrementAndGet(); // 记录新的请求
return true; // 允许请求
}
}
public static void main(String[] args) {
SlidingWindowRateLimiter rateLimiter = new SlidingWindowRateLimiter(10, 1000, 10); // 每秒最多处理10个请求
for (int i = 0; i < 20; i++) {
if (rateLimiter.allowRequest()) {
System.out.println("允许请求 " + (i + 1));
} else {
System.out.println("限流,拒绝请求 " + (i + 1));
}
try {
Thread.sleep(100); // 模拟请求间隔
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Redis + Lua分布式限流
Redis + Lua属于分布式环境下的限流方案,主要利用的是Lua在 Redis中运行能保证原子性。如下示例为一个简单的Lua限流脚本:
local key = KEYS[1]
local limit = tonumber(ARGV[1])
local current = tonumber(redis.call('get', key) or "0")
if current + 1 > limit then
return 0
else
redis.call("INCRBY", key, 1)
redis.call("EXPIRE", key, 1)
return 1
end
脚本解释:
- KEYS[1]:限流的键名,注意,在Lua中,下角标是从 1开始
- ARGV[1]:限流的最大值
- redis.call(‘get’, key):获取当前限流计数。
- redis.call(‘INCRBY’, key, 1):增加限流计数。
- redis.call(‘EXPIRE’, key, 1):设置键的过期时间为 1 秒。
三方限流工具
当我们自己无法实现比较好的限流方案时,成熟的三方框架就是我们比较好的选择,下面列出两个 Java语言比较优秀的框架。
resilience4j
resilience4j 是一个轻量级的容错库,提供了限流、熔断、重试等功能。限流模块 RateLimiter 提供了灵活的限流配置,其优点如下:
- 集成了多种容错机制
- 支持注解方式配置
- 易于与 Spring Boot集成
Sentinel
Sentinel 是阿里巴巴开源的一个功能全面的流量防护框架,提供限流、熔断、系统负载保护等多种功能。其优点如下:
- 功能全面,适用于多种场景
- 强大的监控和控制台
- 与 Spring Cloud 深度集成
总结
本文讲述了以下几种限流方式:
- 计数器
- 滑动窗口
- 漏桶
- 令牌桶
- Redis + Lua 分布式限流
- 三方限流工具
上面的限流方式,主要是针对服务器进行限流,除此之外,我们也可以对客户端进行限流, 比如验证码,答题,排队等方式。
另外,我们也会在一些中间件上进行限流,比如Apache、Tomcat、Nginx等。
在实际的开发中,限流场景略有差异,限流的维度也不一样,比如,有的场景需要根据请求的 URL来限流,有的会对 IP地址进行限流、另外,设备ID、用户ID 也是限流常用的维度,因此,我们需要结合真实业务场景灵活的使用限流方案。