一、Kubernetes网络模型
我们都知道Kubernetes作为容器编排引擎,它有一个强大又复杂的网络模型,也牵引出了Pod网络、Service网络、ClusterIP、NodePort、Ingress等多个概念。这里我们采用杨波老师(架构师杨波)模仿TCP/IP协议栈总结的一个K8S网络模型图来看看K8S的四个抽象层次,从而了解一下K8S的网络。本小节的文字主要引用自杨波老师关于K8S网络模型的文章及CloudMan的《每天5分钟玩转Kubernetes》一书。

根据上图模型中展示的四个层次,从0到3,除了第0层,每一层都是构建于前一层之上。
二、第0层:节点主机互通互联
主要保证K8S节点(物理或虚拟机)之间能够正常IP寻址和互通的网络,这个一般由底层(公有云或数据中心)网络基础设施支持,这里我们无需过多关心。
第0层Node节点网络比较好理解,也就是保证K8s节点(物理或虚拟机)之间能够正常IP寻址和互通的网络,这个一般由底层(公有云或数据中心)网络基础设施支持。第0层我们假定已经存在,所以不展开。
三、第1层:Pod虚拟机互联
在一个Pod中可以运行一个或多个容器,且Pod中所有容器使用同一个网络namespace,即相同的IP和端口空间,可以直接用localhost通信,而且还可以共享存储(本质是通过将Volume挂载到Pod中的每个容器)。
Pod相当于是K8s云平台中的虚拟机,它是K8s的基本调度单位。所谓Pod网络,就是能够保证K8s集群中的所有Pods(包括同一节点上的,也包括不同节点上的Pods),逻辑上看起来都在同一个平面网络内,能够相互做IP寻址和通信的网络,下图是Pod网络的简化概念模型:

Pod网络构建于Node节点网络之上,它又是上层Service网络的基础。为了进一步理解Pod网络,我将对同一节点上的Pod之间的网络,以及不同节点上的Pod之间网络,分别进行剖析。
3.1 同一节点上的Pod网络
前面提到,Pod相当于是K8s云平台中的虚拟机,实际一个Pod中可以住一个或者多个(大多数场景住一个)应用容器,这些容器共享Pod的网络栈和其它资源如Volume。那么什么是共享网络栈?同一节点上的Pod之间如何寻址和互通?我以下图样例来解释:

上图节点上展示了Pod网络所依赖的3个网络设备,eth0是节点主机上的网卡,这个是支持该节点流量出入的设备,也是支持集群节点间IP寻址和互通的设备。docker0是一个虚拟网桥,可以简单理解为一个虚拟交换机,它是支持该节点上的Pod之间进行IP寻址和互通的设备。veth0则是Pod1的虚拟网卡,是支持该Pod内容器互通和对外访问的虚拟设备。docker0网桥和veth0网卡,都是linux支持和创建的虚拟网络设备。
上图Pod1内部住了3个容器,它们都共享一个虚拟网卡veth0。内部的这些容器可以通过localhost相互访问,但是它们不能在同一端口上同时开启服务,否则会有端口冲突,这就是共享网络栈的意思。Pod1中还有一个比较特殊的叫pause的容器,这个容器运行的唯一目的是为Pod建立共享的veth0网络接口。如果你SSH到K8s集群中一个有Pod运行的节点上去,然后运行docker ps,可以看到通过pause命令运行的容器。
Pod的IP是由docker0网桥分配的,例如上图docker0网桥的IP是172.17.0.1,它给第一个Pod1分配IP为172.17.0.2。如果该节点上再启一个Pod2,那么相应的分配IP为172.17.0.3,如果再启动Pod可依次类推。因为这些Pods都连在同一个网桥上,在同一个网段内,它们可以进行IP寻址和互通,如下图所示:
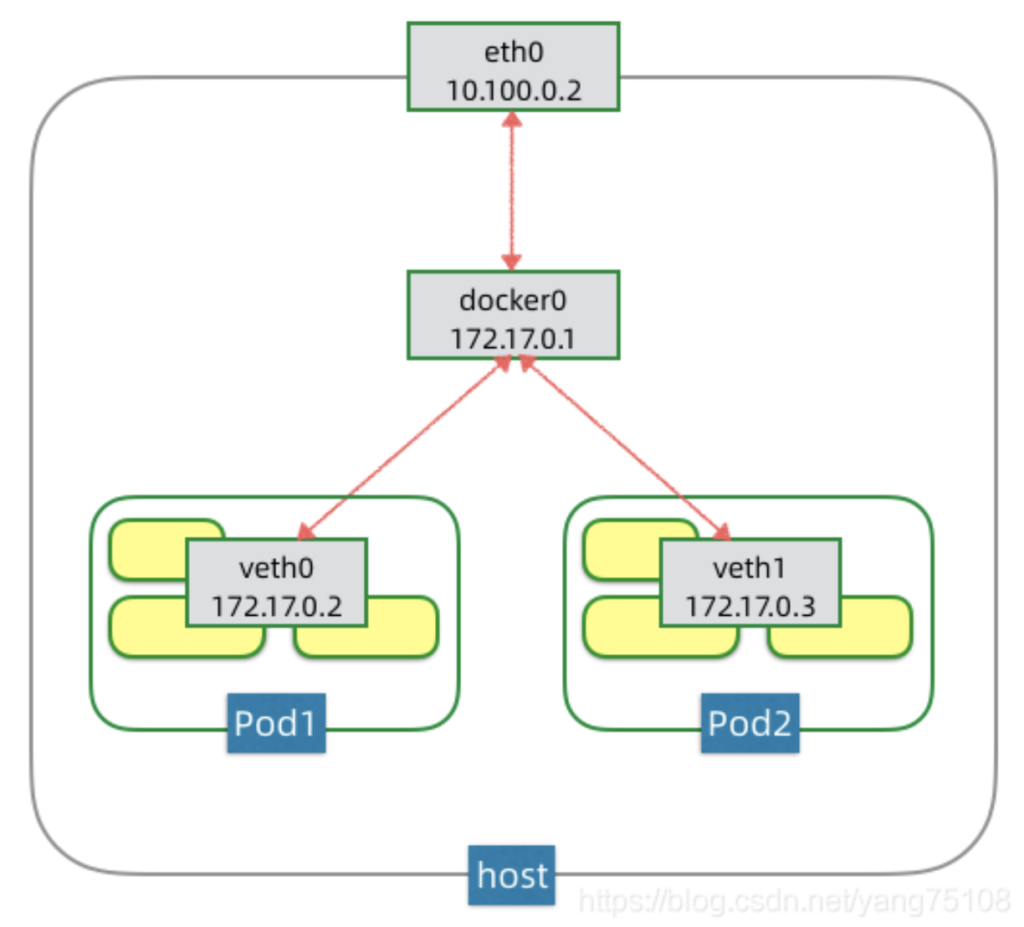
从上图我们可以看到,节点内Pod网络在172.17.0.0/24这个地址空间内,而节点主机在10.100.0.0/24这个地址空间内,也就是说Pod网络和节点网络不在同一个网络内,那么不同节点间的Pod该如何IP寻址和互通呢?下一节我们来分析这个问题。
3.2 不同节点间的Pod网络
现在假设我们有两个节点主机,host1(10.100.0.2)和host2(10.100.0.3),它们在10.100.0.0/24这个地址空间内。host1上有一个PodX(172.17.0.2),host2上有一个PodY(172.17.1.3),Pod网络在172.17.0.0/16这个地址空间内。注意,Pod网络的地址,是由K8s统一管理和分配的,保证集群内Pod的IP地址唯一。我们发现节点网络和Pod网络不在同一个网络地址空间内,那么host1上的PodX该如何与host2上的PodY进行互通?

实际上不同节点间的Pod网络互通,有很多技术实现方案,底层的技术细节也很复杂。为了简化描述,我把这些方案大体分为两类,一类是路由方案,另外一类是覆盖(Overlay)网络方案。
如果底层的网络是你可以控制的,比如说企业内部自建的数据中心,并且你和运维团队的关系比较好,可以采用路由方案,如下图所示:
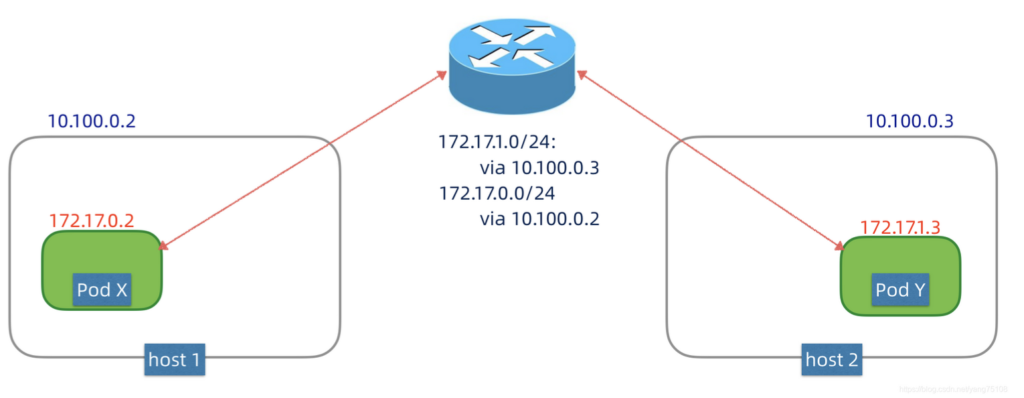
这个方案简单理解,就是通过路由设备为K8s集群的Pod网络单独划分网段,并配置路由器支持Pod网络的转发。例如上图中,对于目标为172.17.1.0/24这个范围内的包,转发到10.100.0.3这个主机上,同样,对于目标为172.17.0.0/24这个范围内的包,转发到10.100.0.2这个主机上。当主机的eth0接口接收到来自Pod网络的包,就会向内部网桥转发,这样不同节点间的Pod就可以相互IP寻址和通信。这种方案依赖于底层的网络设备,但是不引入额外性能开销。
如果底层的网络是你无法控制的,比如说公有云网络,或者企业的运维团队不支持路由方案,可以采用覆盖(Overlay)网络方案,如下图所示:
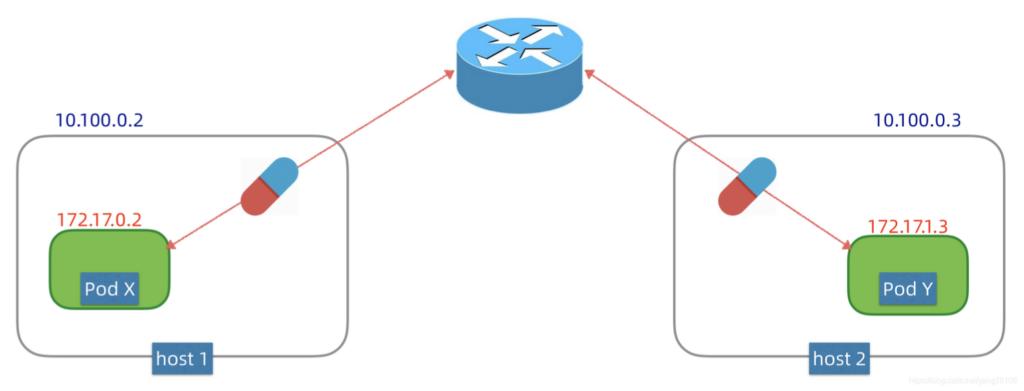
所谓覆盖网络,就是在现有网络之上再建立一个虚拟网络,实现技术有很多,例如flannel/weavenet等等,这些方案大都采用隧道封包技术。简单理解,Pod网络的数据包,在出节点之前,会先被封装成节点网络的数据包,当数据包到达目标节点,包内的Pod网络数据包会被解封出来,再转发给节点内部的Pod网络。这种方案对底层网络没有特别依赖,但是封包解包会引入额外性能开销。
3.3 CNI简介
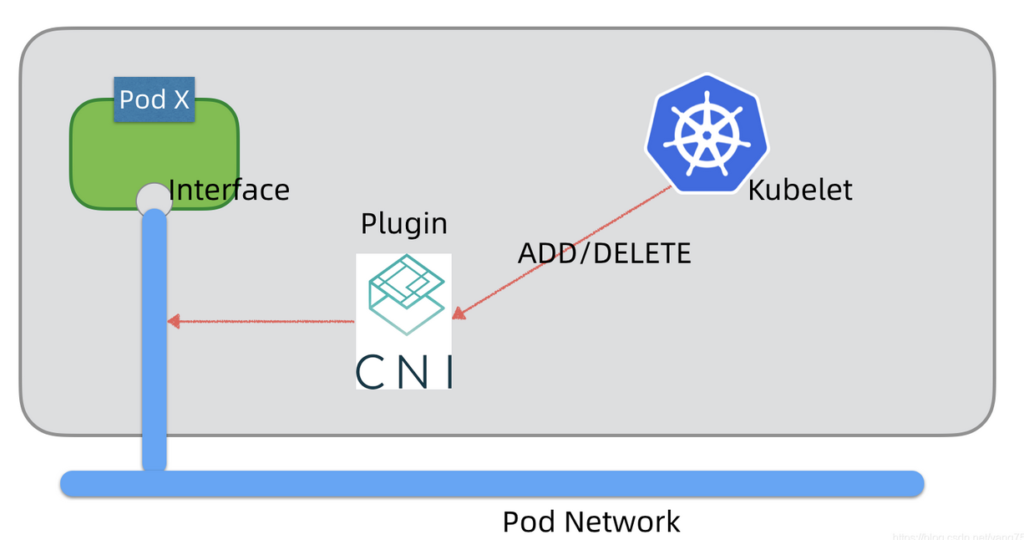
考虑到Pod网络实现技术众多,为了简化集成,K8s支持CNI(Container Network Interface)标准,不同的Pod网络技术可以通过CNI插件形式和K8s进行集成。节点上的Kubelet通过CNI标准接口操作Pod网路,例如添加或删除网络接口等,它不需要关心Pod网络的具体实现细节。
3.4 总结
- K8s的网络可以抽象成四层网络,第0层节点网络,第1层Pod网络,第2层Service网络,第3层外部接入网络。除了第0层,每一层都构建于上一层之上。
- 一个节点内的Pod网络依赖于虚拟网桥和虚拟网卡等linux虚拟设备,保证同一节点上的Pod之间可以正常IP寻址和互通。一个Pod内容器共享该Pod的网络栈,这个网络栈由pause容器创建。
- 不同节点间的Pod网络,可以采用路由方案实现,也可以采用覆盖网络方案。路由方案依赖于底层网络设备,但没有额外性能开销,覆盖网络方案不依赖于底层网络,但有额外封包解包开销。
- CNI是一个Pod网络集成标准,简化K8s和不同Pod网络实现技术的集成。
有了Pod网络,K8s集群内的所有Pods在逻辑上都可以看作在一个平面网络内,可以正常IP寻址和互通。但是Pod仅仅是K8s云平台中的虚拟机抽象,最终,我们需要在K8s集群中运行的是应用或者说服务(Service),而一个Service背后一般由多个Pods组成集群,这时候就引入了服务发现(Service Discovery)和负载均衡(Load Balancing)等问题。
四、第2层:服务发现和负载均衡
在K8S集群中,Pod的IP并不是固定的,可能会频繁地销毁和创建实例,为了解决此问题,Service提供了访问Pod的抽象层。即无论后端Pod如何变化,Service都作为稳定的前端对外提供服务。此外,Service还提供了高可用和负载均衡的功能,它负责将请求转发给正确的Pod。

4.1 Service网络概念模型
我们假定第1层Pod网络已经存在,下图是K8s的第2层Service网络的简化概念模型:
我们假定在K8s集群中部署了一个Account-App应用,这个应用由4个Pod(虚拟机)组成集群一起提供服务,每一个Pod都有自己的PodIP和端口。我们再假定集群内还部署了其它应用,这些应用中有些是Account-App的消费方,也就说有Client Pod要访问Account-App的Pod集群。这个时候自然引入了两个问题:
- 服务发现(Service Discovery): Client Pod如何发现定位Account-App集群中Pod的IP?况且Account-App集群中Pod的IP是有可能会变的(英文叫ephemeral),这种变化包括预期的,比如Account-App重新发布,或者非预期的,例如Account-App集群中有Pod挂了,K8s对Account-App进行重新调度部署。
- 负载均衡(Load Balancing):Client Pod如何以某种负载均衡策略去访问Account-App集群中的不同Pod实例?以实现负载分摊和HA高可用。
实际上,K8s通过在Client和Account-App的Pod集群之间引入一层Account-Serivce抽象,来解决上述问题:
- 服务发现:Account-Service提供统一的ClusterIP来解决服务发现问题,Client只需通过ClusterIP就可以访问Account-App的Pod集群,不需要关心集群中的具体Pod数量和PodIP,即使是PodIP发生变化也会被ClusterIP所屏蔽。注意,这里的ClusterIP实际是个虚拟IP,也称Virtual IP(VIP)。
- 负载均衡:Account-Service抽象层具有负载均衡的能力,支持以不同策略去访问Account-App集群中的不同Pod实例,以实现负载分摊和HA高可用。K8s中默认的负载均衡策略是RoundRobin,也可以定制其它复杂策略。
K8s中为何要引入Service抽象?背后的原理是什么?后面我将以技术演进视角来解释这些问题。
4.2 服务发现技术演进
DNS域名服务是一种较老且成熟的标准技术,实际上DNS可以认为是最早的一种服务发现技术。
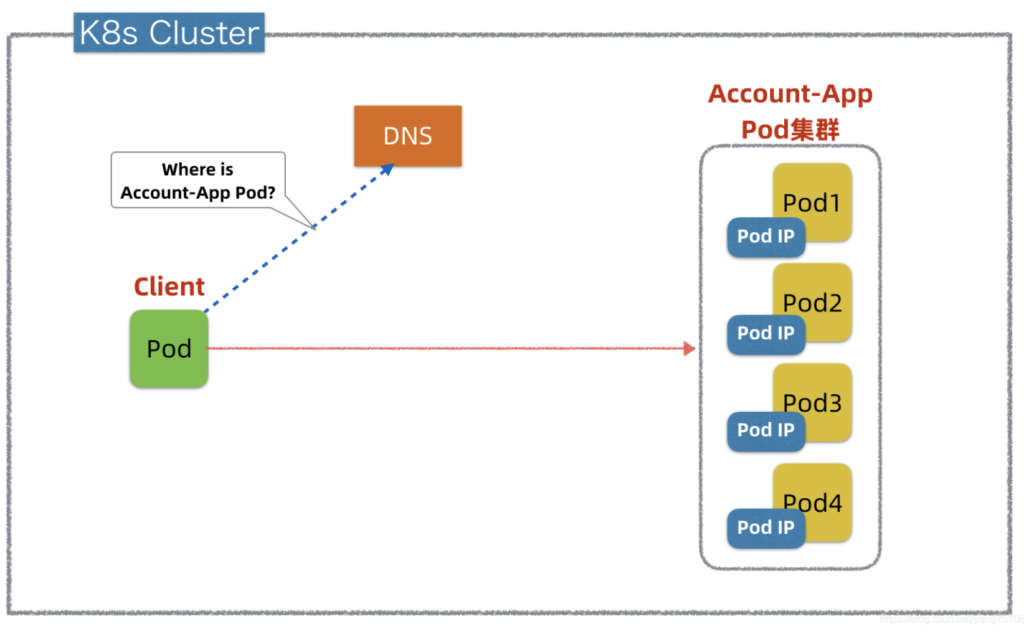
在K8s中引入DNS实现服务发现其实并不复杂,实际K8s本身就支持Kube-DNS组件。假设K8s引入DNS做服务发现(如上图所示),运行时,K8s可以把Account-App的Pod集群信息(IP+Port等)自动注册到DNS,Client应用则通过域名查询DNS发现目标Pod,然后发起调用。这个方案不仅简单,而且对Client也无侵入(目前几乎所有的操作系统都自带DNS客户端)。但是基于DNS的服务发现也有如下问题:
- 不同DNS客户端实现功能有差异,有些客户端每次调用都会去查询DNS服务,造成不必要的开销,而有些客户端则会缓存DNS信息,默认超时时间较长,当目标PodIP发生变化时(在容器云环境中是常态),存在缓存刷新不及时,会导致访问Pod失效。
- DNS客户端实现的负载均衡策略一般都比较简单,大都是RoundRobin,有些则不支持负载均衡调用。
考虑到上述不同DNS客户端实现的差异,不在K8s控制范围内,所以K8s没有直接采用DNS技术做服务发现。注意,实际K8s是引入Kube-DNS支持通过域名访问服务的,不过这是建立在CusterIP/Service网络之上,这个我后面会展开。
另外一种较新的服务发现技术,是引入Service Registry+Client配合实现,在当下微服务时代,这是一个比较流行的做法。目前主流的产品,如Netflix开源的Eureka + Ribbon,HashiCorp开源的Consul,还有阿里新开源Nacos等,都是这个方案的典型代表。
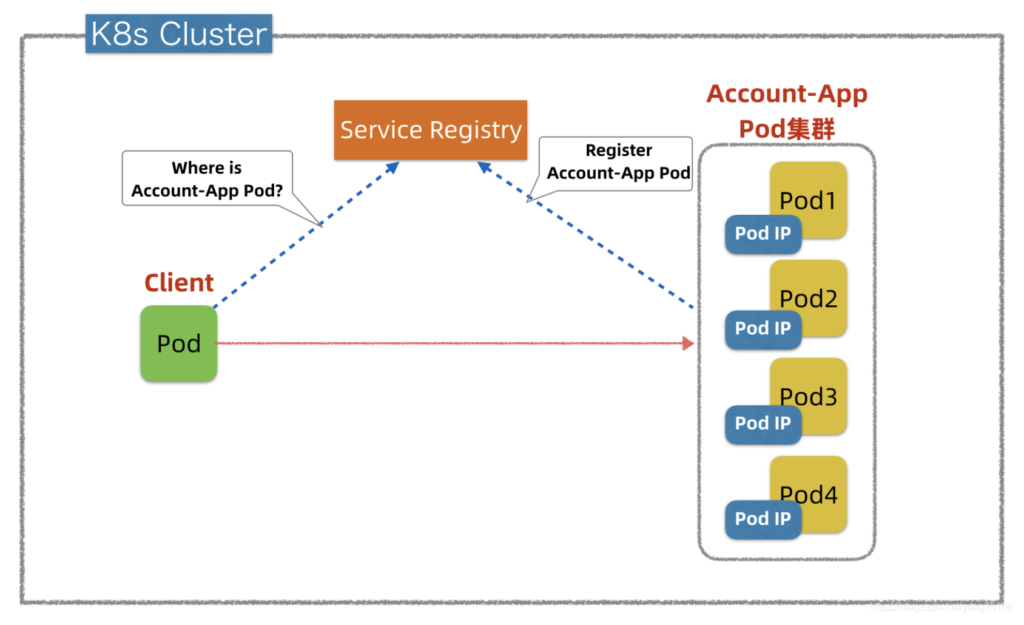
在K8s中引入Service Registry实现服务发现也不复杂,K8s自身带分布式存储etcd就可以实现Service Registry。假设K8s引入Service Registry做服务发现(如上图所示),运行时K8s可以把Account-App和Pod集群信息(IP + Port等)自动注册到Service Registry,Client应用则通过Service Registry查询发现目标Pod,然后发起调用。这个方案也不复杂,而且客户端可以实现灵活的负载均衡策略,但是需要引入客户端配合,对客户应用有侵入性,所以K8s也没有直接采用这种方案。
K8s虽然没有直接采用上述方案,但是它的Service网络实现是在上面两种技术的基础上扩展演进出来的。它融合了上述方案的优点,同时解决了上述方案的不足,下节我会详细剖析K8s的Service网络的实现原理。
4.3 K8s的Service网络原理
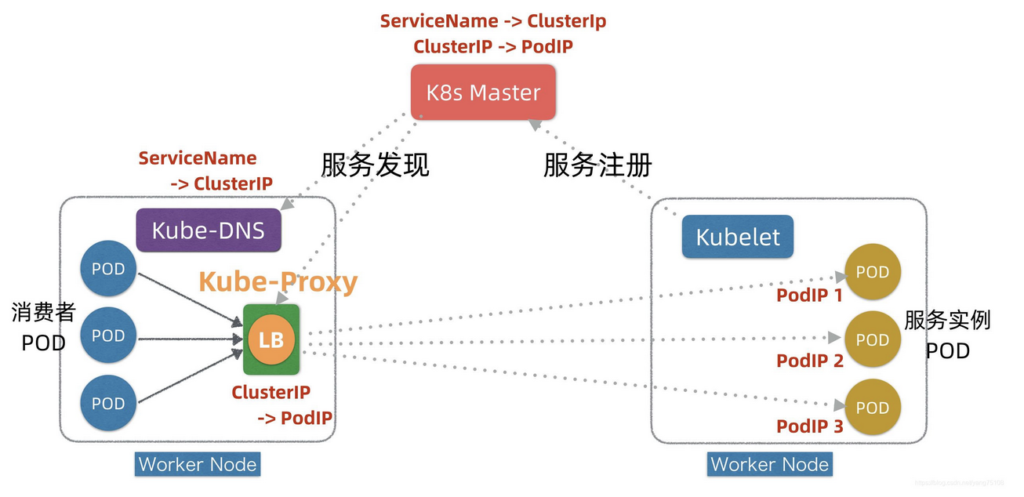
前面提到,K8s的服务发现机制是在上节讲的Service Registry + DNS基础上发展演进出来的,下图展示K8s服务发现的简化原理:

在K8s平台的每个Worker节点上,都部署有两个组件,一个叫Kubelet,另外一个叫Kube-Proxy,这两个组件+Master是K8s实现服务注册和发现的关键。下面我们看下简化的服务注册发现流程。
- 首先,在服务Pod实例发布时(可以对应K8s发布中的Kind: Deployment),Kubelet会负责启动Pod实例,启动完成后,Kubelet会把服务的PodIP列表汇报注册到Master节点。
- 其次,通过服务Service的发布(对应K8s发布中的Kind: Service),K8s会为服务分配ClusterIP,相关信息也记录在Master上。
- 第三,在服务发现阶段,Kube-Proxy会监听Master并发现服务ClusterIP和PodIP列表映射关系,并且修改本地的linux iptables转发规则,指示iptables在接收到目标为某个ClusterIP请求时,进行负载均衡并转发到对应的PodIP上。
- 运行时,当有消费者Pod需要访问某个目标服务实例的时候,它通过ClusterIP发起调用,这个ClusterIP会被本地iptables机制截获,然后通过负载均衡,转发到目标服务Pod实例上。
实际消费者Pod也并不直接调服务的ClusterIP,而是先调用服务名,因为ClusterIP也会变(例如针对TEST/UAT/PROD等不同环境的发布,ClusterIP会不同),只有服务名一般不变。为了屏蔽ClusterIP的变化,K8s在每个Worker节点上还引入了一个KubeDNS组件,它也监听Master并发现服务名和ClusterIP之间映射关系,这样, 消费者Pod通过KubeDNS可以间接发现服务的ClusterIP。
注意,K8s的服务发现机制和目前微服务主流的服务发现机制(如Eureka + Ribbon)总体原理类似,但是也有显著区别(这些区别主要体现在客户端):
- 首先,两者都是采用客户端代理(Proxy)机制。和Ribbon一样,K8s的代理转发和负载均衡也是在客户端实现的,但Ribbon是以Lib库的形式嵌入在客户应用中的,对客户应用有侵入性,而K8s的Kube-Proxy是独立的,每个Worker节点上有一个,它对客户应用无侵入。K8s的做法类似ServiceMesh中的边车(sidecar)做法。
- 第二,Ribbon的代理转发是穿透的,而K8s中的代理转发是iptables转发,虽然K8s中有Kube-Proxy,但它只是负责服务发现和修改iptables(或ipvs)规则,实际请求是不穿透Kube-Proxy的。注意早期K8s中的Kube-Proxy代理是穿透的,考虑到有性能损耗和单点问题,后续的版本就改成不穿透了。
- 第三,Ribbon实现服务名到服务实例IP地址的映射,它只有一层映射。而K8s中有两层映射,Kube-Proxy实现ClusterIP->PodIP的映射,Kube-DNS实现ServiceName->ClusterIP的映射。
个人认为,对比目前微服务主流的服务发现机制,K8s的服务发现机制抽象得更好,它通过ClusterIP统一屏蔽服务发现和负载均衡,一个服务一个ClusterIP,这个模型和传统的IP网络模型更贴近和易于理解。ClusterIP也是一个IP,但这个IP后面跟的不是一个服务实例,而是一个服务集群,所以叫集群ClusterIP。同时,它对客户应用无侵入,且不穿透没有额外性能损耗。
4.4 总结一下
- K8s的Service网络构建于Pod网络之上,它主要目的是解决服务发现(Service Discovery)和负载均衡(Load Balancing)问题。
- K8s通过一个ServiceName+ClusterIP统一屏蔽服务发现和负载均衡,底层技术是在DNS+Service Registry基础上发展演进出来。
- K8s的服务发现和负载均衡是在客户端通过Kube-Proxy + iptables转发实现,它对应用无侵入,且不穿透Proxy,没有额外性能损耗。
- K8s服务发现机制,可以认为是现代微服务发现机制和传统Linux内核机制的优雅结合。
有了Service抽象,K8s中部署的应用都可以通过一个抽象的ClusterIP进行寻址访问,并且消费方不需要关心这个ClusterIP后面究竟有多少个Pod实例,它们的PodIP是什么,会不会变化,如何以负载均衡方式去访问等问题。但是,K8s的Service网络只是一个集群内可见的内部网络,集群外部是看不到Service网络的,也无法直接访问。而我们发布应用,有些是需要暴露出去,要让外网甚至公网能够访问的,这样才能对外提供服务。K8s如何将内部服务暴露出去? , 请接着往下看。
五、第3层:外部流量接入
K8s的Service网络只是一个集群内部网络,集群外部是无法直接访问的。为此,想要将应用暴露出去让公网能够访问,K8S提供了两种方式:
在讲到K8s如何接入外部流量的时候,大家常常会听到NodePort,LoadBalancer和Ingress等概念,这些概念都是和K8s外部流量接入相关的,它们既是不同概念,同时又有关联性。下面我们分别解释这些概念和它们之间的关系。
5.1 NodePort
先提前强调一下,NodePort是K8s将内部服务对外暴露的基础,后面的LoadBalancer底层有赖于NodePort。
之前我们讲了K8s网络的4层抽象,Service网络在第2层,节点网络在第0层。实际上,只有节点网络是可以直接对外暴露的,具体暴露方式要看数据中心或公有云的底层网络部署,但不管采用何种部署,节点网络对外暴露是完全没有问题的。那么现在的问题是,第2层的Service网络如何通过第0层的节点网络暴露出去?我们可以回看一下K8s服务发现的原理图,如下图所示,然后不妨思考一下,K8s集群中有哪一个角色,即掌握Service网络的所有信息,可以和Service网络以及Pod网络互通互联,同时又可以和节点网络打通?
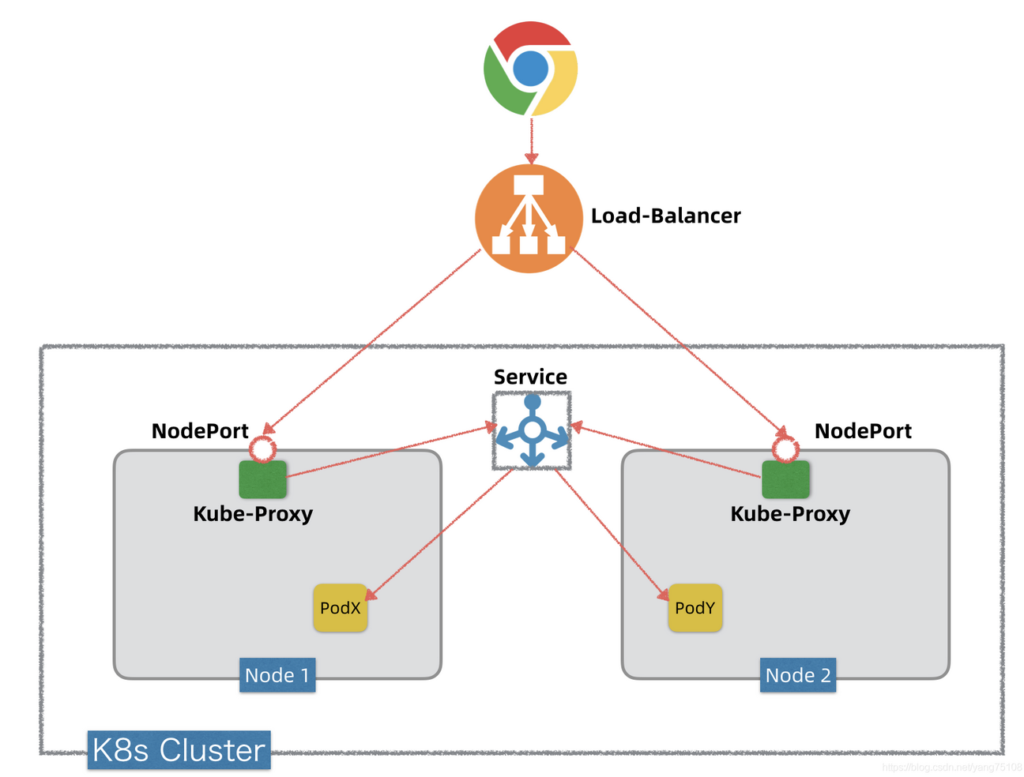
答案是Kube-Proxy。上一篇我们提到Kube-Proxy是K8s内部服务发现的一个关键组件,事实上,它还是K8s将内部服务暴露出去的关键组件。Kube-Proxy在K8s集群中所有Worker节点上都部署有一个,它掌握Service网络的所有信息,知道怎么和Service网络以及Pod网络互通互联。如果要将Kube-Proxy和节点网络打通(从而将某个服务通过Kube-Proxy暴露出去),只需要让Kube-Proxy在节点上暴露一个监听端口即可。这种通过Kube-Proxy在节点上暴露一个监听端口,将K8s内部服务通过Kube-Proxy暴露出去的方式,术语就叫NodePort(顾名思义,端口暴露在节点上)。下图是通过NodePort暴露服务的简化概念模型。
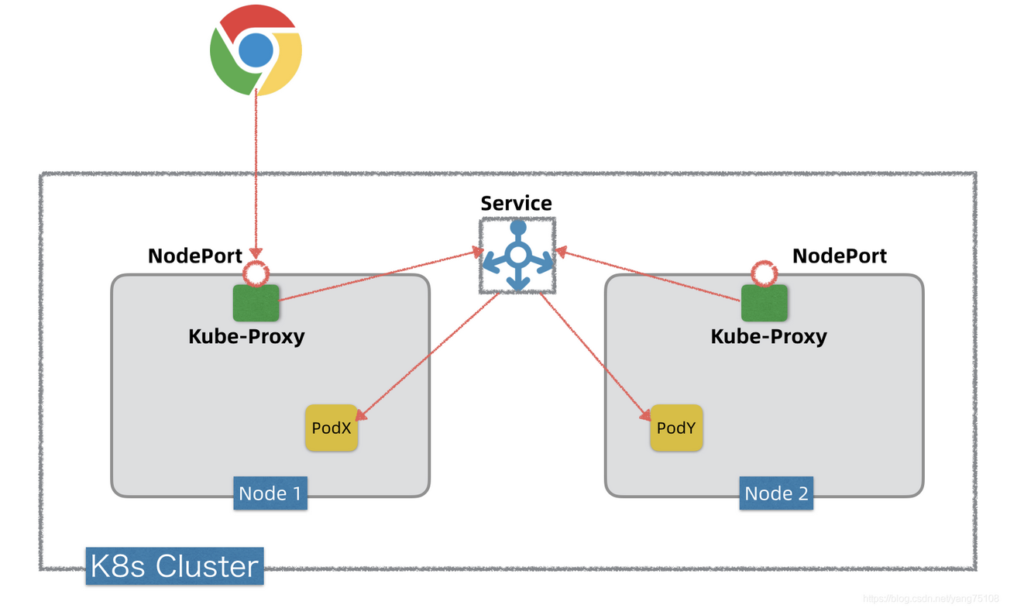
如果我们要将K8s内部的一个服务通过NodePort方式暴露出去,可以将服务发布(kind: Service)的type设定为NodePort,同时指定一个30000~32767范围内的端口。服务发布以后,K8s在每个Worker节点上都会开启这个监听端口。这个端口的背后是Kube-Proxy,当K8s外部有Client要访问K8s集群内的某个服务,它通过这个服务的NodePort端口发起调用,这个调用通过Kube-Proxy转发到内部的Servcie抽象层,然后再转发到目标Pod上。Kube-Proxy转发以及之后的环节,可以和上一篇《Kubernetes网络三部曲~Service网络》的内容对接起来。注意,为了直观形象,上图的Service在K8s集群中被画成一个独立组件,实际是没有独立Service这样一个组件的,只是一个抽象概念,如果要理解这个抽象的底层实现细节,可以回头看上一图的K8s服务发现原理。
5.2 LoadBalancer
上面我们提到,将K8s内部的服务通过NodePort方式暴露出去,K8s会在每个Worker节点上都开启对应的NodePort端口。逻辑上看,K8s集群中的所有节点都会暴露这个服务,或者说这个服务是以集群方式暴露的(实际支持这个服务的Pod可能就分布在其中有限几个节点上,但是因为所有节点上都有Kube-Proxy,所以所有节点都知道该如何转发)。既然是集群,就会涉及负载均衡问题,谁负责对这个服务的负载均衡访问?答案是需要引入负载均衡器(Load Balancer)。下图是通过LoadBalancer,将服务对外暴露的概念模型。
假设我们有一套阿里云K8s环境,要将K8s内部的一个服务通过LoadBalancer方式暴露出去,可以将服务发布(Kind: Service)的type设定为LoadBalancer。服务发布后,阿里云K8s不仅会自动创建服务的NodePort端口转发,同时会自动帮我们申请一个SLB,有独立公网IP,并且阿里云K8s会帮我们自动把SLB映射到后台K8s集群的对应NodePort上。这样,通过SLB的公网IP,我们就可以访问到K8s内部服务,阿里云SLB负载均衡器会在背后做负载均衡。
值得一提的是,如果是在本地开发测试环境里头搭建的K8s,一般不支持Load Balancer也没必要,因为通过NodePort做测试访问就够了。但是在生产环境或者公有云上的K8s,例如GCP或者阿里云K8s,基本都支持自动创建Load Balancer。
5.3 Ingress
有了前面的NodePort + LoadBalancer,将K8s内部服务暴露到外网甚至公网的需求就已经实现了,那么为啥还要引入Ingress这样一个概念呢?它起什么作用?
我们知道在公有云(阿里云/AWS/GCP)上,公网LB+IP是需要花钱买的。我们回看上图的通过LoadBalancer(简称LB)暴露服务的方式,发现要暴露一个服务就需要购买一个独立的LB+IP,如果要暴露十个服务就需要购买十个LB+IP,显然,从成本考虑这是不划算也不可扩展的。那么,有没有办法只需购买一个(或者少量)的LB+IP,但是却可以按需暴露更多服务出去呢?答案其实不复杂,就是想办法在K8内部部署一个独立的反向代理服务,让它做代理转发。谷歌给这个内部独立部署的反向代理服务起了一个奇怪的名字,就叫Ingress,它的简化概念模型如下图所示:

Ingress就是一个特殊的Service,通过节点的HostPort(80/443)暴露出去,前置一般也有LB做负载均衡。Ingress转发到内部的其它服务,是通过集群内的Service抽象层/ClusterIP进行转发,最终转发到目标服务Pod上。Ingress的转发可以基于Path转发,也可以基于域名转发等方式,基本上你只需给它设置好转发路由表即可,功能和Nginx无本质差别。
注意,上图的Ingress概念模型是一种更抽象的画法,隐去了K8s集群中的节点,实际HostPort是暴露在节点上的。
所以,Ingress并不是什么神奇的东西,首先,它本质上就是K8s集群中的一个比较特殊的Service(发布Kind: Ingress)。其次,这个Service提供的功能主要就是7层反向代理(也可以提供安全认证,监控,限流和SSL证书等高级功能),功能类似Nginx。第三,这个Service对外暴露出去是通过HostPort(80/443),可以和上面LoadBalancer对接起来。有了这个Ingress Service,我们可以做到只需购买一个LB+IP,就可以通过Ingress将内部多个(甚至全部)服务暴露出去,Ingress会帮忙做代理转发。
那么哪些软件可以做这个Ingress?传统的Nginx/Haproxy可以,现代的微服务网关Zuul/SpringCloudGateway/Kong/Envoy/Traefik等等都可以。当然,谷歌别出心裁给这个东东起名叫Ingress,它还是做了一些包装,以简化对Ingress的操作。如果你理解了原理,那么完全可以用Zuul或者SpringCloudGateway,或者自己定制开发一个反向代理,来替代这个Ingress。部署的时候以普通Service部署,将type设定为LoadBalancer即可,如下图所示:

注意,Ingress是一个7层反向代理,如果你要暴露的是4层服务,还是需要走独立LB+IP方式。
5.4 Kubectl Proxy & Port Forward
上面提到的服务暴露方案,包括NodePort/LoadBalancer/Ingress,主要针对正式生产环境。如果在本地开发测试环境,需要对本地部署的K8s环境中的服务或者Pod进行快速调试或测试,还有几种简易办法,这边一并简单介绍下,如下图所示:

- 办法一,通过kubectl proxy命令,在本机上开启一个代理服务,通过这个代理服务,可以访问K8s集群内的任意服务。背后,这个Kubectl代理服务通过Master上的API Server间接访问K8s集群内服务,因为Master知道集群内所有服务信息。这种方式只限于7层HTTP转发。
- 办法二,通过kubectl port-forward命令,它可以在本机上开启一个转发端口,间接转发到K8s内部的某个Pod的端口上。这样我们通过本机端口就可以访问K8s集群内的某个Pod。这种方式是TCP转发,不限于HTTP。
- 办法三,通过kubectl exec命令直接连到Pod上去执行linux命令,功能类似docker exec。
六、总结
- NodePort是K8s内部服务对外暴露的基础,LoadBalancer底层有赖于NodePort。NodePort背后是Kube-Proxy,Kube-Proxy是沟通Service网络、Pod网络和节点网络的桥梁。
- 将K8s服务通过NodePort对外暴露是以集群方式暴露的,每个节点上都会暴露相应的NodePort,通过LoadBalancer可以实现负载均衡访问。公有云(如阿里云/AWS/GCP)提供的K8s,都支持自动部署LB,且提供公网可访问IP,LB背后对接NodePort。
- Ingress扮演的角色是对K8s内部服务进行集中反向代理,通过Ingress,我们可以同时对外暴露K8s内部的多个服务,但是只需要购买1个(或者少量)LB。Ingress本质也是一种K8s的特殊Service,它也通过HostPort(80/443)对外暴露。
- 通过Kubectl Proxy或者Port Forward,可以在本地环境快速调试访问K8s中的服务或Pod。
- K8s的Service发布主要有3种type,type=ClusterIP,表示仅内部可访问服务,type=NodePort,表示通过NodePort对外暴露服务,type=LoadBalancer,表示通过LoadBalancer对外暴露服务(底层对接NodePort,一般公有云才支持)。
至此,Kubernetes网络三部曲全部讲解完成,希望这三篇文章对你理解和用好K8s有帮助。下表是对三部曲的浓缩总结,是希望大家带走记住的:

More:关于K8S网络的更多基本原理与讲解,强力推荐阅读波波老师的以下文章:
- Kubernetes网络三部曲-Pod网络(From 杨波老师)
- Kubernetes网络三部曲-Service网络(From 杨波老师)
- Kubernetes网络三部曲-外部接入网络(From 杨波老师)